Authors: Fangwei Zhu, Shangqing Tu, Jiaxin Shi, Juanzi Li, Lei Hou, Tong Cui
Paper reference: https://aclanthology.org/2021.acl-long.356.pdf
Contribution
This paper proposes a two-stage Topic-guided Wikipedia Abstract Generation model (TWAG) that guides topic-aware abstract summarization. Specifically, TWAG first divides documents into paragraphs and assigns a topic for each paragraph. Then, it generates the abstract in a sentence-wise manner based on predicted time-wise topic-aware representation for a sentence.
Experiments show that TWAG can generate comprehensive abstracts and outperform state-of-the-art models which view Wikipedia abstracts as plain text.
Details
Task Formulation
The task is to automatically generate Wikipedia abstracts based on the related documents collected from referred websites or search engines.
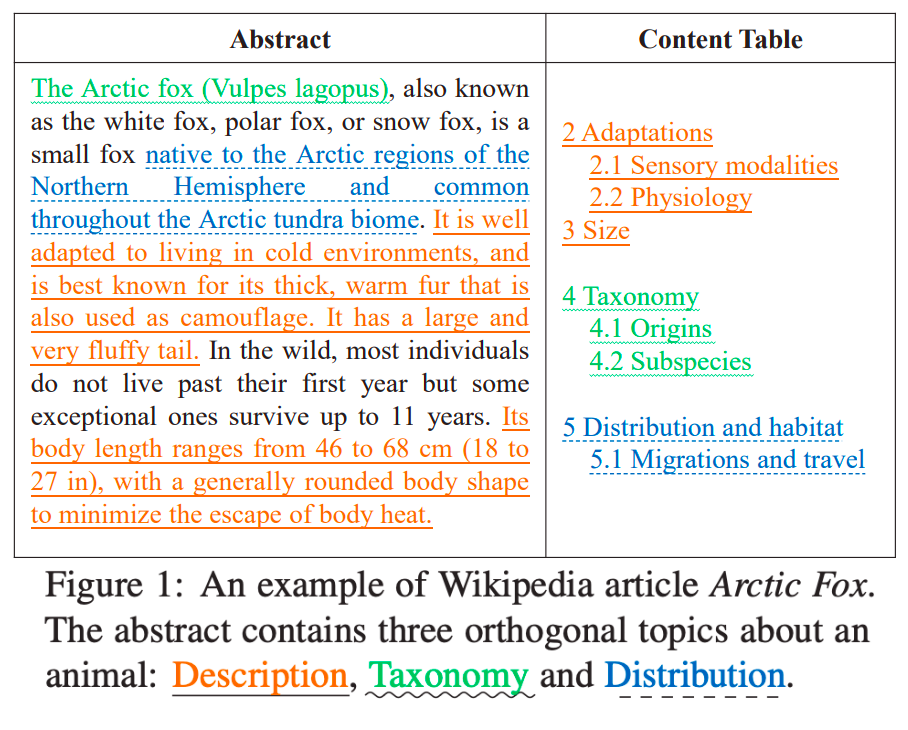
Based on the observation that a Wikipedia article normally describes an object from different aspects/topics and that the abstract semantically corresponds to these topics, the paper proposes to utilize the topic information to guide sumarization.
Method
Overview
The paper proposes a two-stage model TWAG (Topic-guided Wikipedia Abstract Generation model) to guide abstractive summarization using topic information.
- Stage 1: Train a topic detector to predict a topic for each paragraph (normally a paragraph expresses relatively complete and compact semantics).
- Stage 2: Encode each topic separately and generate the abstract in a sentence-wise manner.
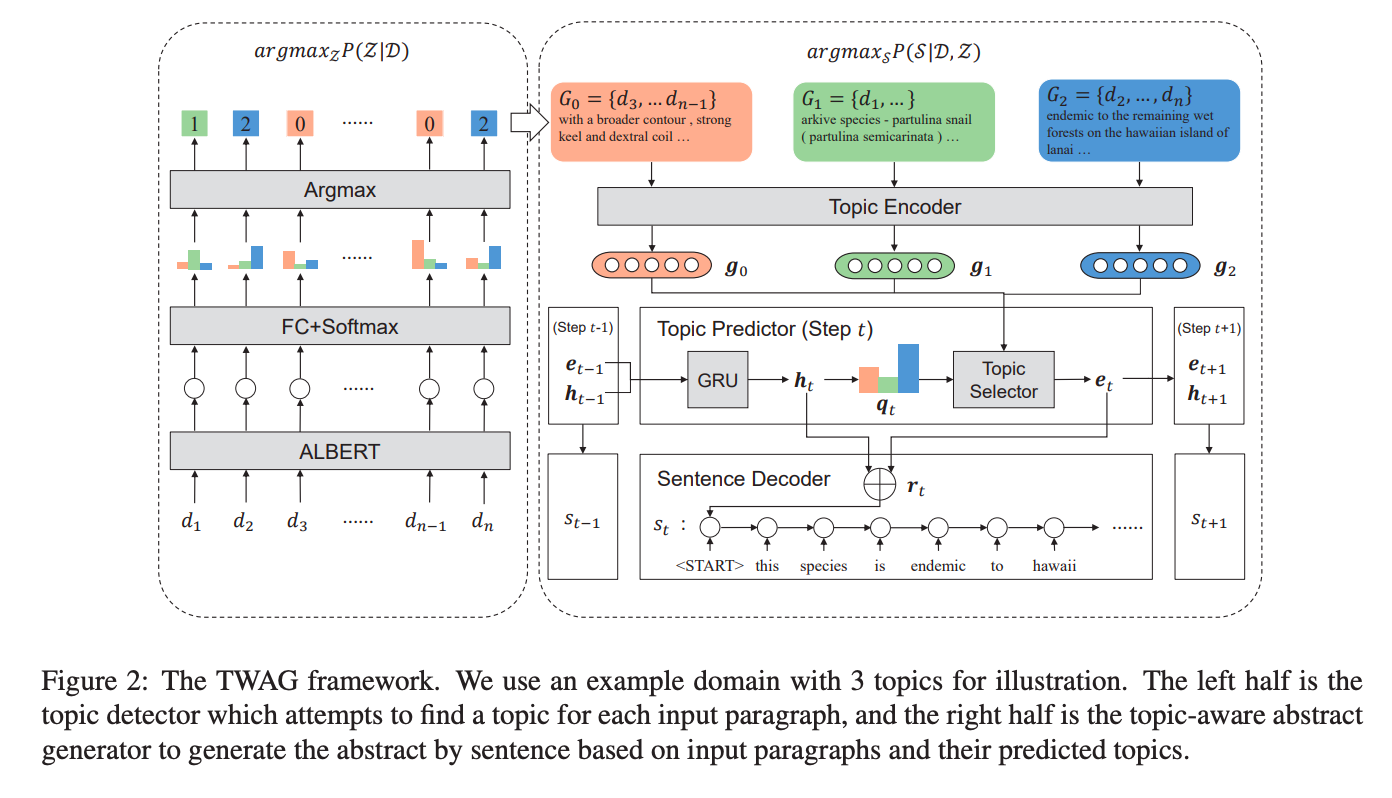
Stage 1 - Topic Detection
The paper render topic detection as a classification problem. Given a paragraph $d_i$, the classification task is to predict the topic for $d_i$. The paper uses ALBert as the classification model.
Stage 2 - Topic-aware Abstract Generation
Topic-aware abstract generator consist of three modules.
Topic Encoder
Topic detection assigns each paragraph a topic, and all paragraphs sharing the same topic are grouped together to form a topic-specific text group $G_j$.
This paper uses BiGRU to encode each topic-specific text group $G_j$ as a hidden state $\mathbf{g_j}$.
Topic Predictor
TWAG generates the summary in a sentence-by-sentence manner. At each time step $t$, the topic predictor further fuses information from all hidden representations of text groups ${\mathbf{g_j}}$ to a topic-aware hidden representation $\mathbf{r_t}$.
Note: Given that Wikipedia abstract sentences normally contain mixed topics, the paper decides to fuse information from all text groups (weighted differently each time apparently) at each time step.
Sentence Decoder
The paper leverages a Pointer-Generator to generate a summary sentence $s_t$ with topic-aware representation $\mathbf{r_t}$ obtained from topic predictor as the inital decoder hidden state.
Finally, sentences having an overlap of over 50% with other sentences are removed to reduce redundancy.