Authors: Philippe Laban, Tobias Schnabel, Paul N. Bennett, Marti A. Hearst
Paper reference: https://arxiv.org/pdf/2111.09525.pdf
Contribution
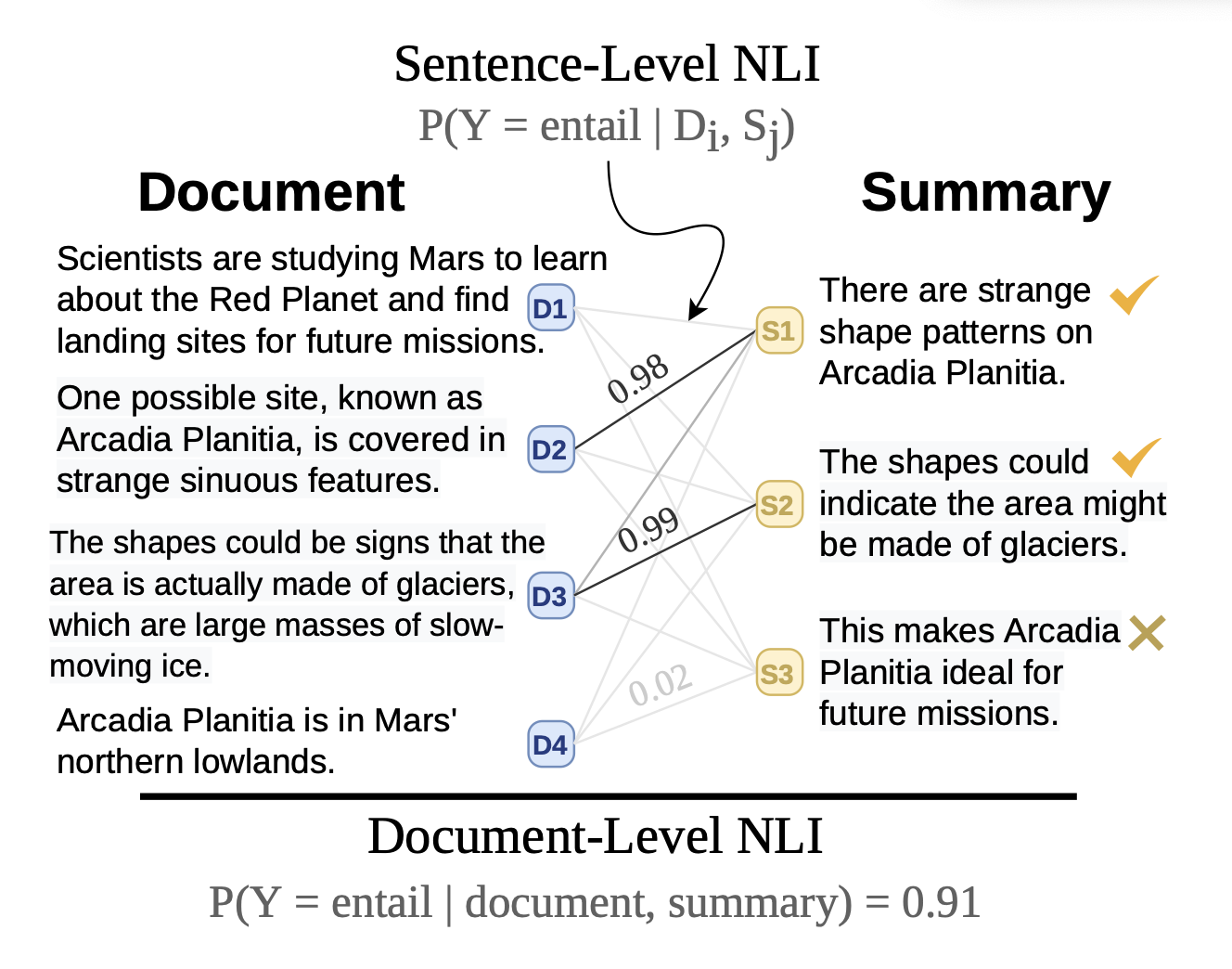
This paper proposes two models $SummaC_{ZS}$ (directly interpretable), $SummaC_{Conv}$ for inconsistency detection based on the aggregation of sentence-level entailment scores for each pair of input document and summary sentences.
Experiments show that the choice of granularity affect the performance of models and combinations like (one sentence, one sentence) and (two sentences, one sentence) lead to the best performance (as NLI datasets are predominantly represented at the sentence level). Also the choice of NLI dataset has a stronger influence on overall performance compared to model architectures.
Introduce a SUMMAC Benchmark by standardizing existing six summary inconsistency detection datasets.
Details
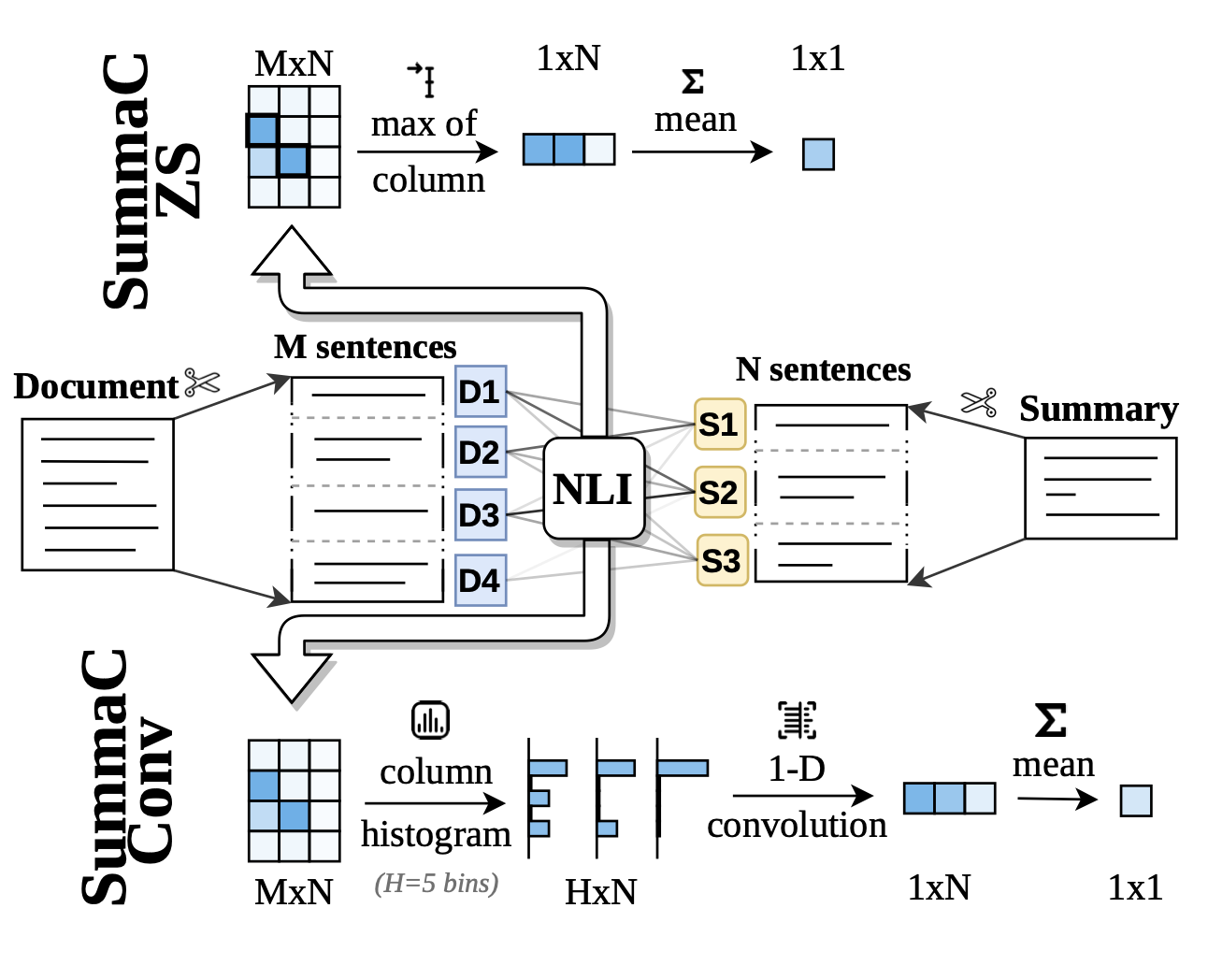
For each of (document, summary) pair, the document and the summary are divided into sentences and form a pair matrix.
-
$SummaC_{ZS}$ performs zero-shot aggregation by combining sentence-level scores using max and mean operators (parameters free). Disadvantage: sensitive to extrema, which can be noisy due to the presence of outliers and the imperfect nature of NLI models.
-
$SummaC_{Conv}$ is a trained model consisting of a single learned convolution layer to take into account the distribution of entailment scores for each summary sentence.
Limitations
In the case of a summary performing a sentence fusion operation, an NLI model might not be able to correctly predict entailment of the fused sentence, seeing only one sen- tence at a time.
Is it possible to dynamically selecting a granular level for each (document, summary) pair?