Information Extraction v.s. Relation Extraction
Information Extraction: Information extraction is the task of automatically extracting structured information from unstructured and/or semi-structured machine-readable documents and other electronically represented sources.
Relation extraction (RE) is an important task in IE. It focuses on extracting relations between entities. A complete relation RE system consists of
- a named entity recognizer to identify named entities from text.
- an entity linker to link entities to existing knowledge graphs.
- a relational classifier to determine relations between entities by given context (most difficult and important).
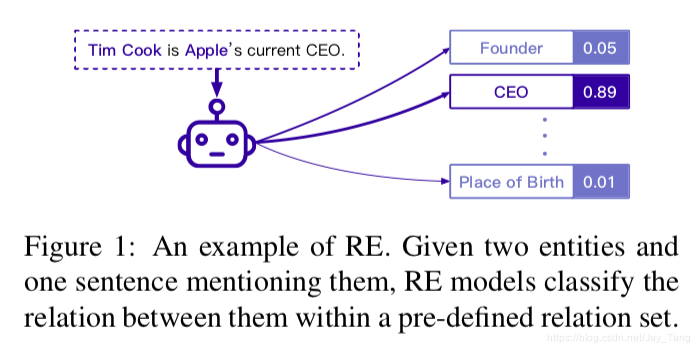
Existing Works of RE
RE methods follows the typical supervised setting, from early pattern-based methods, statistical approaches, to recent neural models.
Pattern-based Methods
The early methods use sentence analysis tools to identify syntactic elements in text, then automatically construct pattern rules from these elements. Later work involves larger corpora, more formats of patterns and more efficient ways of extraction.
Statistical Relation Extraction Models
Statistical Methods requires less human efforts so that statistical relation extraction (SRE) has been extensively studied. Approaches includes:
- feature-based methods which design lexical, syntactic and semantic features for entity pairs and their corresponding context (hard to design features).
- kernel-based methods measures the similarities between relation representations and textual instances (hard to design kernel functions).
- Graphical methods abstract the dependencies between entities, text and relations in the form of directed acyclic graphs, and then use inference models to identify the correct relations (still limited model capacities).
- embedding models. Encode text into low-dimensional semantic spaces and extract relations from textual embeddings. E.g. Knowledge Graph (KG) embeddings.
Neural Relation Extraction Methods
The performance of SOTA RE models. The adoption of neural models began in 2013.
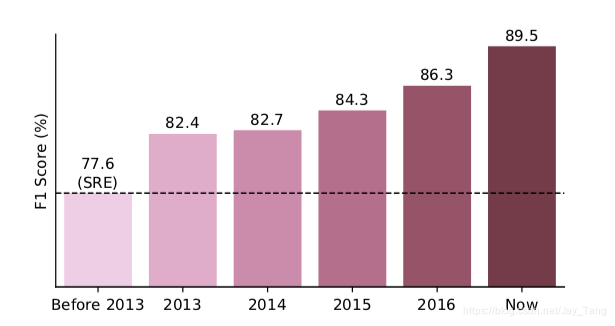
Neural relation extraction (NRE) models can effectively capture textual information and generalize to wider range of data. NRE mainly utilizes both word embeddings and positional embeddings and focus on designing and utilizing various network architectures to capture the relational semantics within text. Methods includes:
- Recursive Neural Networks. Learn compositional representations for sentences recursively.
- Convolutional neural networks (CNNs). Model local textual patterns.
- Recurrent neural networks (RNNs). Handle long sequential data.
- Graph neural networks (GNNs). Build word/entity graphs for reasoning.
- Attention-based neural networks. Aggregate global relational information.
Currently, Transformers and Pre-trained LM models achieves SOTA on intra-sentence RE.
Future Directions
Despite the success of existing RE methods, most of them still work in a simplified setting. These methods mainly focus on training models with large amounts of human annotations to classify two given entities within one sentence into pre-defined relations. However, the real world is much more complicated than this simple setting:
- collecting high-quality human annotations is expensive and time-consuming.
- many long-tail relations cannot provide large amounts of training examples.
- most facts are expressed by long context consisting of multiple sentences.
- using a pre-defined set to cover those relations with open-ended growth is difficult.
Utilizing More Data
The researchers have formed a consensus that utilizing more data is a potential way towards more powerful RE models.
Distant supervision (DS) assumption has been used to automatically label data by aligning existing KGs with plain text. For any entity pair in KGs, sentences mentioning both the entities will be labeled with their corresponding relations in KGs.
Here is an illustration of DS relation extraction. With the fact (Apple Inc., product, iPhone), DS finds all sentences mentioning the two entities and annotates them with the relation product, which inevitably brings noise labels.

Methods to Denoise DS Data
- Adopt multi-instance learning by combining sentences with same entity pairs and then selecting informative instances from them.
- Incorporating extra context information such as KGs.
- Utilize sophisticated mechanisms and training strategies to enhance distantly supervised NRE models.
Open Problem for Utilizing More Data
- Existing DS methods focus on denoising auto-labeled instances. Explore better DS schemes is valuable.
- Perform unsupervised or semi-supervised learning for utilizing large-scale unlabeled data as well as using knowledge from KGs and introducing human experts in the loop.
Performing More Efficient Learning
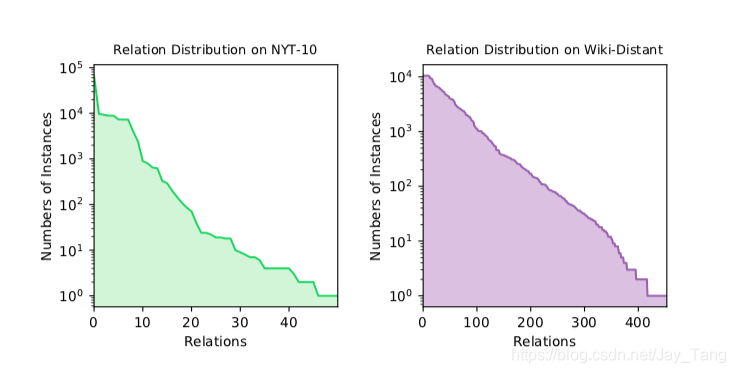
Real-world relation distributions are long-tail and most relations have very limited relational facts and corresponding sentences. We can see the long tail distributions from two DS datasets in the following figure:
Few-shot Learning
Few-shot learning is a good fit for learning long-tail relations efficiently. It trains good representations of instances or learns ways of fast adaptation from existing large-scale data, and then transfer to new tasks.
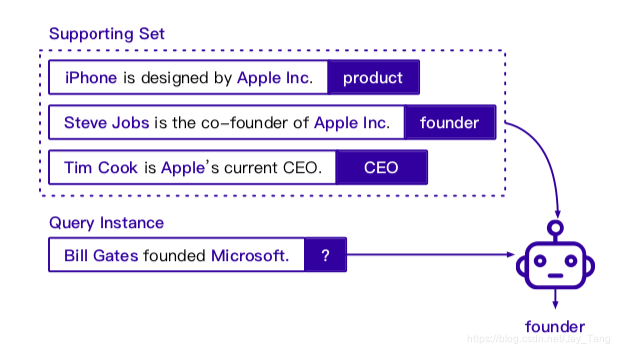
A typical few-shot learning setting is the N-way K-shot setting, where models are given N random-sampled new relations, along with K training examples for each relation. Here is an example. Give a few instances for new relation types, few-shot RE models classify query sentences into one of the given relations.
Here are a few challenges for few-shot learning:
- Few-shot domain adaptation.
- Few-shot none-of-the-above detection. Conventional few-shot models have the difficulty to form a good representation for the none-of-the-above (NOTA) relation in the N-way K-shot setting. Therefore, it is crucial to study how to identify NOTA instances .
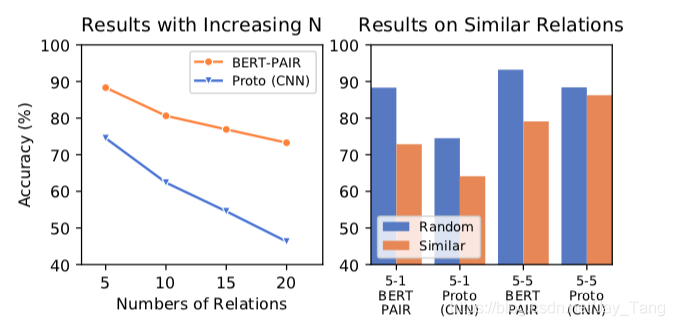
- Few-shot RE may result in a easy classification task if total amount of relations is small. As the following figure shows, as the number of relations increase, the performance drops.
- Current models cannot truly understand relations similar in semantics.
Handling More Complicated Context
Most existing methods focus on intra-sentence RE and thus are inadequate for identifying relational facts expressed in a long document. Extracting relations from complicated context is a challenging task requiring reading, memorizing and reasoning for discovering relational facts across multiple sentences.
Here is a post (Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs) I wrote for explaining using GNN on document-level relation extraction task.
Orienting More Open Domains
Our world undergoes growth of relations and it is not possible to pre-specify all relations by human experts. Thus, we need RE systems that do not rely on pre-defined relation schemas and can work in open scenarios. Here are current explorations in handling open relations:
- Open information extraction (Open IE), which extracts relation phrases and arguments (entities) from text.

- Relation discovery, which discover unseen relation types from unsupervised data. Here is an example of casting relation discovery as a clustering task.
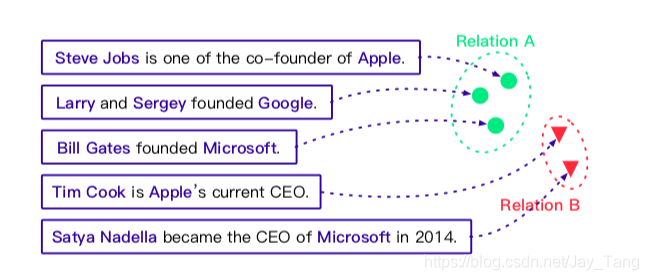
Note: There are many redundant extracted relations. Normalizing these phrases is crucial for downstream tasks. For example, relations on (Barack Obama, was born in , Honolulu) and (Obama, place of birth, Honolulu) are actually identical. So they should be normalized.
Reference:
- More Data, More Relations, More Context and More Openness: A Review and Outlook for Relation Extraction. https://arxiv.org/pdf/2004.03186.pdf.
- Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs. https://arxiv.org/pdf/1909.00228.pdf.
- Distant supervision for relation extraction without labeled data. https://www.aclweb.org/anthology/P09-1113.pdf.