Authors: Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig
Paper reference: https://arxiv.org/pdf/2107.13586.pdf
Introduction
To use prompt-based models to perform prediction tasks, the original input $x$ is modified using a template into a textual string prompt $x'$ that has some unfilled slots, and then the language model is used to probabilistically fill the unfilled information to obtain a final string $\hat{x}$, from which the final output $y$ can be derived. The advantage of this method is that, given a suite of appropriate prompts, a single LM trained in an entirely unsupervised fashion can be used to solve a great number of tasks. However, this method introduces the necessity for prompt engineering, finding the most appropriate prompt to allow a LM to solve the task at hand.
It allows the language model to be pre-trained on massive amounts of raw text, and by defining a new prompting function the model is able to perform few-shot or even zero-shot learning, adapting to new scenarios with few or no labeled data. In this paradigm, downstream tasks are reformulated to look more like those solved during the original LM training with the help of a textual prompt. In this way, by selecting the appropriate prompts we can manipulate the model behavior so that the pre-trained LM itself can be used to predict the desired output, sometimes even without any additional task-specific training.
Prompt Basics
A prompting function $f_{\text {prompt }}(\cdot)$ is applied to modify the input text $x$ into a prompt $x^{\prime}=f_{\text {prompt}}(x)$. This function consists of a two step process: \
- Apply a template, which is a textual string that has two slots: an input slot $[X]$ for input $x$ and an answer slot $[Z]$ for an intermediate generated answer text $z$ that will later be mapped into $y$. \
- Fill slot $[X]$ with the input text $x$.
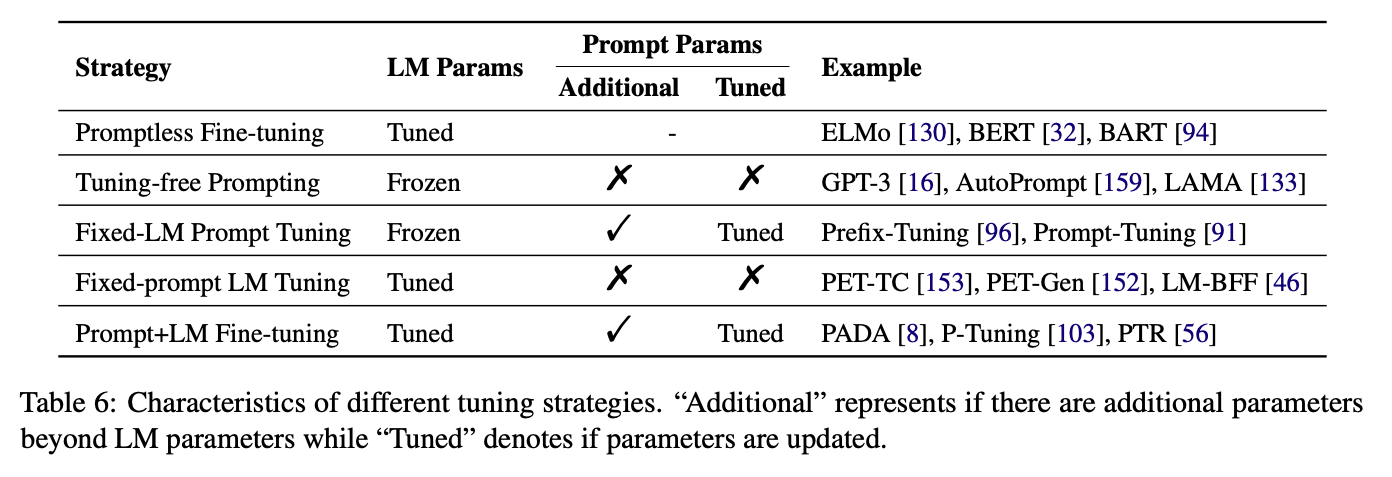
Prompt Engineering
Prompt engineering is the process of creating a prompting function $f_{\text {prompt}}(x)$ that results in the most effective performance on the downstream task. Annotated training samples are often used in the construction or validation of the prompts that the downstream task will use.
Shapes of prompts: close prompts and prefix prompts.
Manual Template Engineering
Manually create intuitive templates based on human introspection. Some drawbacks: (1) creating and experimenting with these prompts takes time and experience. (2) Optimal prompts are not easy to discover.
Automated Template Learning
It can be devided into (1) discrete prompts and continuous prompts; (2) static and dynamic prompts.
Discrete Prompts
- Prompt Mining: Find templates given a set of training inputs $x$ and outputs $y$ by scraping a large text corpus (e.g. Wikipedia).
- Prompt Paraphrasing: Take in an existing seed prompt (e.g. manually constructed or mined), paraphrases it into a set of other candidate prompts, then picks ones that achieve the highest training accuracy.
- Gradient-based Search: Trigger the underlying pre-trained LM to generate the desired target prediction by a gradient-based search over actual tokens.
- Prompt Generation: Use generation models to generate templates.
Continuous Prompts
- Prefix Tuning: Prepends a sequence of trainable continuous task-specific vectors to the input.
- Tuning Initialized with Discrete Prompts: Initialize the search for a continuous prompt using a prompt that has already been created or discovered using discrete prompt search methods.
- Hard-Soft Prompt Hybrid Tuning: Insert some tunable embeddings into a manual prompt template.
Answer Engineering
Answer engineering aims to search for an answer space $Z$ and a map to the original output $Y$ that results in an effective predictive model.
Shapes of answers: tokens, spans, and sentences.
Manual Answer Design
Unconstrained Spaces
In many cases, the answer space $Z$ is the space of all tokens. In these cases, it is most common to use the identity mapping.
Constrained Spaces
This is often performed for tasks with a limited label space such as text classification. In these cases, it is necessary to have a mapping between the answer $Z$ and the underlying class $Y$.
As with manually created prompts, it is possible that manually created answers are sub-optimal for getting the LM to achieve ideal prediction performance.
Automated Answer Search
Discrete Answer Search
- Answer Paraphrasing: Start with an initial answer space $Z'$ , and then use paraphrasing to expand this answer space to broaden its coverage.
- Prune-then-Search: An initial pruned answer space of several plausible answers $Z'$ is generated, and then an algorithm further searches over this pruned space to select a final set of answers.
Continuous Answer Search
Very few works exist.
Multi-Prompt Learning
Extend the single prompt learning to the use multiple prompts.
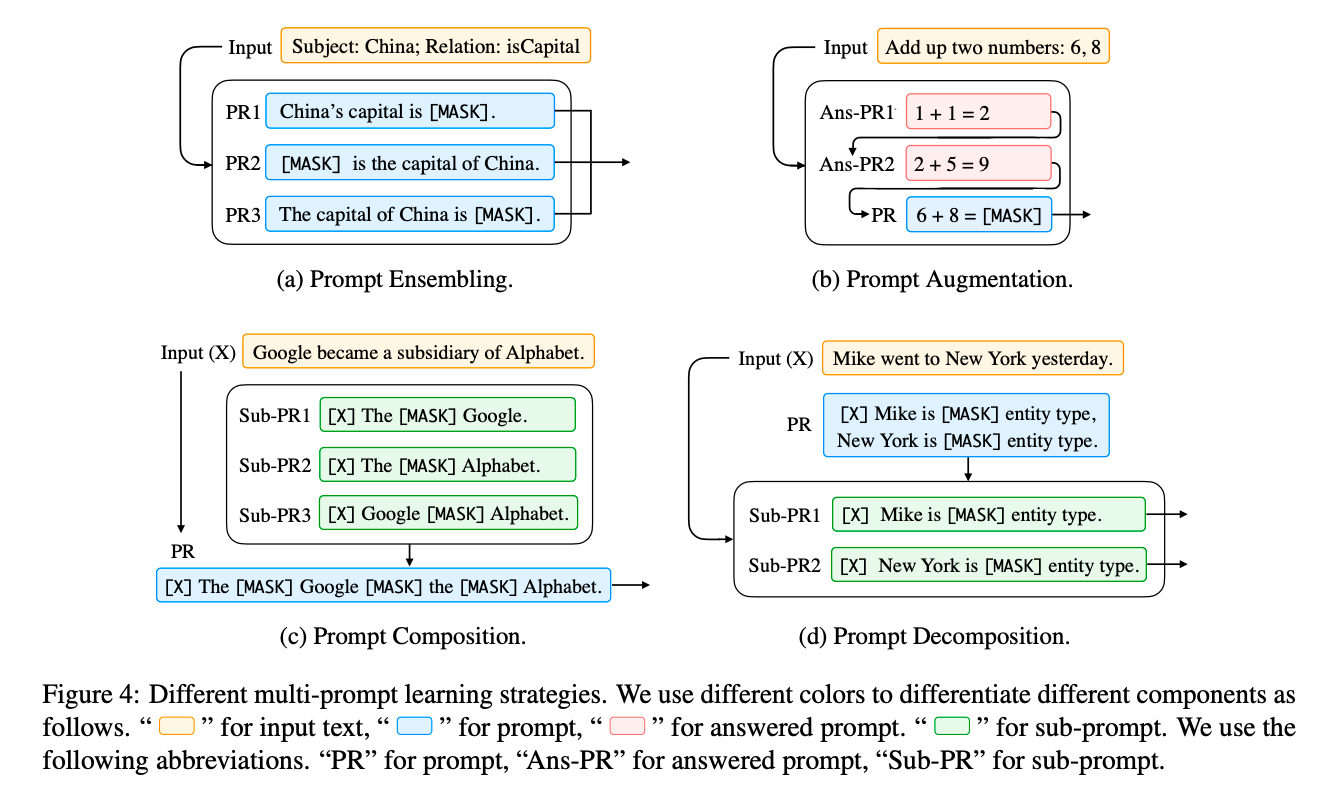
Prompt Ensembling
Advantages:
(1) leverage the complementary advantages of different prompts;
(2) alleviate the cost of prompt engineering, since choosing one best-performing prompt is challenging;
(3) stabilize performance on downstream tasks.
- Uniform averaging: Combine the predictions by taking the average of probabilities from different prompts.
- Weighted averaging: Each prompt is associated with a weight. The weights are typically pre-specified based on prompt performance or optimized using a training set.
- Majority voting: Combine results for classification tasks.
- etc.
Prompt Augmentation
Prompt augmentation provides a few additional answered prompts that can be used to demonstrate how the LM should provide the answer to the actual prompt instantiated with the input $x$. It leverages the template and answer, while larger context learning does not.
- Sample Selection: The choice of examples used in this few-shot scenario can result in very different performance, ranging from near state-of-the-art accuracy on some tasks to near random guess.
- Sample Ordering: The order of answered prompts provided to the model plays an important role in model performance.
Prompt Composition & Prompt Decomposition
Use when tasks are based on more fundamental subtasks or multiple predictions should be performed for one sample (e.g., sequence labeling).
Training Strategies for Prompting Methods