Contribution
Authors: Darsh Shah, Lili Yu, Tao Lei, Regina Barzilay
Paper Reference: https://aclanthology.org/2021.naacl-main.411.pdf
This paper develops a system for generating summaries that capture the consensus (similarities and contradictions) in multiple input documents. Specifically, instead of training an end-to-end generation model, it proposes a Content Selection and Aggregation model to identify key contents that should be put in the summary and then a Surface Realization model to convert these contents into a summary.
By separately training two components, the framework requires few parallel examples for training. Generated summaries from the proposed framework are evaluated to be faithful and cognizant of consensus in the input documents. The model is also capable of fusing new studies into original generated summary.
Detail
The paper uses a Food and Health summary dataset HealthLine, which consists of scientific abstracts as inputs and human written summaries as outputs. The task is to generate a text summary $y$ for a food from multiple scientific abstracts $X$.
Model
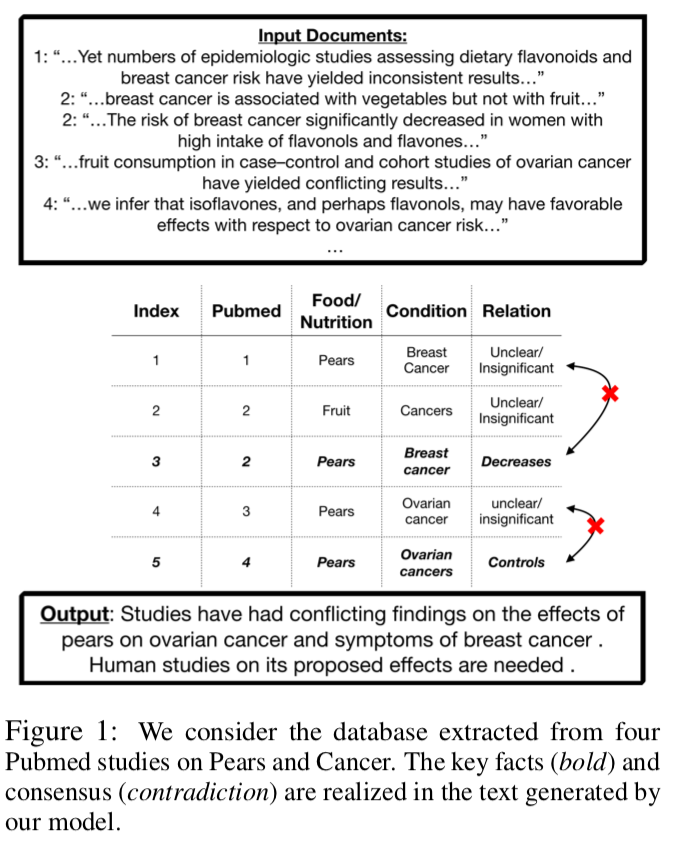
Entity extraction and relation classification
For both input documents $X$ and the summary $y$, food health entity-entity relations are extracted from entity extraction and relation classification modules trained on corresponding annotations, and then converted into a mini-database of relation tuples.
Content Selection and Aggregation
For each instance, the content selection model takes produced mini-database of entity-entity relation tuples as input, and (1) identifies subset of key tuples $C$; (2) then identifies aggregation operator $O$.
Content Selection. The paper uses a reinforcement learning algorithm to train the content selection model. It’s trained to gradually add more entity-entity relation pairs to selected content $C$, and encourages the model to concisely select relevant and diverse content.
Consensus Aggregation. The paper lists a few pre-defined rules to determine the aggregation operator of $C$ in context of all entity-entity relation tuples in the mini-database. There are four aggregation operator: (1) Under-Reported; (2) Population Scoping; (3) Contradiction; and (4) Agreement.
Surface Realization
The surface realization model performs summarization and is trained using
(1) ground truth summary $y$;
(2) all entity-entity relation tuples from source document;
(3) aggregation operator.
During inference, the summary is conditioned on (guided by)
(1) selected content $C$;
(2) the aggregation operator $O$.