Authors: Sewon Min, Mike Lewis, Hannaneh Hajishirzi, Luke Zettlemoyer
Paper reference: https://arxiv.org/pdf/2108.04106.pdf
Contribution
This paper introduces a noisy channel approach by using large language models for few-shot text classification, via either in-context demonstration or prompt tuning, with no or very limited updates to the model parameters. Experiments show that channel models have superior performance compare to their direct counterparts since they have lower variance and significantly higher worst-case accuracy.
The paper provides recommendations for using channel prompt tuning when:
(1) Training size is small;
(2) Data is imbalanced or there are large number of classes;
(3) required to generalize to unseen labels;
(4) Task is close to language modeling.
Details
Formulation and Definition
This paper focuses on eleven text classification tasks. The goal is to learn a function $f: \mathcal{X} \rightarrow \mathcal{C}$, where $\mathcal{X}$ is a set of texts and $\mathcal{C}=\{c_{1} \ldots c_{m}\}$ is a set of labels. Meanwhile, assume a pre-defined verbalizer $v: \mathcal{C} \rightarrow \mathcal{X}$ which maps each label into text. The paper considers the following three formulations with a causal language model (GPT-2 in the paper):
- Direct model $P(c_i|x)$.
- Direct++ model $\frac{P\left(c_{i} \mid x\right)}{P\left(c_{i} \mid \text{NULL}\right)}$ is a calibrated verision of Direct model and performs better.
- Channel model $\propto P(x|c_i)$. Intuitively, channel models are required to explain every word in the input, potentially amplifying training signals in the low data regime.
In the few-shot setup, a model takes $K$ training examples $\mathcal{D}=\left\{\left(x^{1}, c^{1}\right), \cdots,\left(x^{K}, c^{K}\right)\right\}$. Examples are sampled uniformly (do not consider label imbalance).
Demonstration Methods
In the following three demonstration methods, there are no trainable parameters.

- Zero-shot.
- Concat-based demonstrations. Prepend a concatenation of $K$ training examples ${{x^j, v(c^j)}}$ to the input so that a language model can learn the task setup from the input.
- Ensemble-based demonstrations. Instead of concatenation, multiply probabilities from an LM $K$ times conditioned on one training example at a time. It eliminates the dependency on the ordering of training examples, which has been shown to significantly impact the model performance.
Each model formulation (from previous section) can pair with one of these demonstration methods, resulting in 9 combinations in paper’s experiments.
Experiments show that:
(1) in direct models, ensemble based method is better.
(2) in the few-shot setting, channel models always outperform direct models.
(3) channel models always outperform significantly under few-shot setting comparing to zero-shot setting.
Tuning Methods
The paper explores three tuning methods which update limited number of model parameters. Two of them worths attention.
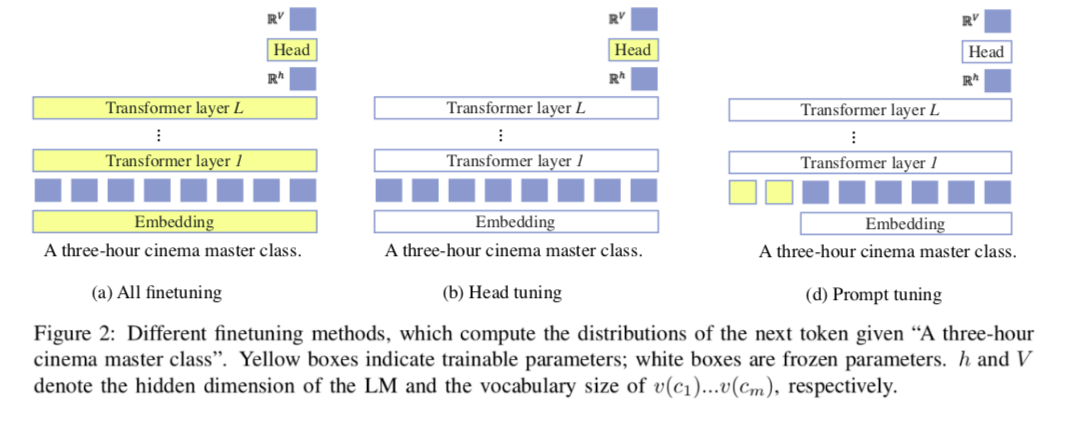
- Head Tuning. Head tuning finetunes the head - the fully connected layer that transfers the dimensions from hidden representation size $h$ to vocal size $\mathcal{V}$. Other params of LM are fixed.
- Prompt Tuning. Prepend $n$ prompt tokens $u_1 … u_n$ to the input. The parameters in the LM are frozen except the embeddings of $u_{1} \ldots u_{n}$.
- direct models compute $P\left(c_{i} | x\right)=$ $P_{\mathrm{LM}}\left(v\left(c_{i}\right) | u_{1} \ldots u_{n}, x\right)$;
- channel models compute $P\left(x | c_{i}\right)=P_{\mathrm{LM}}\left(x | u_{1} \ldots u_{n}, v\left(c_{i}\right)\right) .$
Experiments show that:
(1) channel models consistently outperform direct models under prompt tuning.
(2) head tuning is a very strong method, although ignored in previous works.
(3) prompt tuning outperforms the demonstration method by using channel models. (Demonstration methods v.s. Tuning methods)
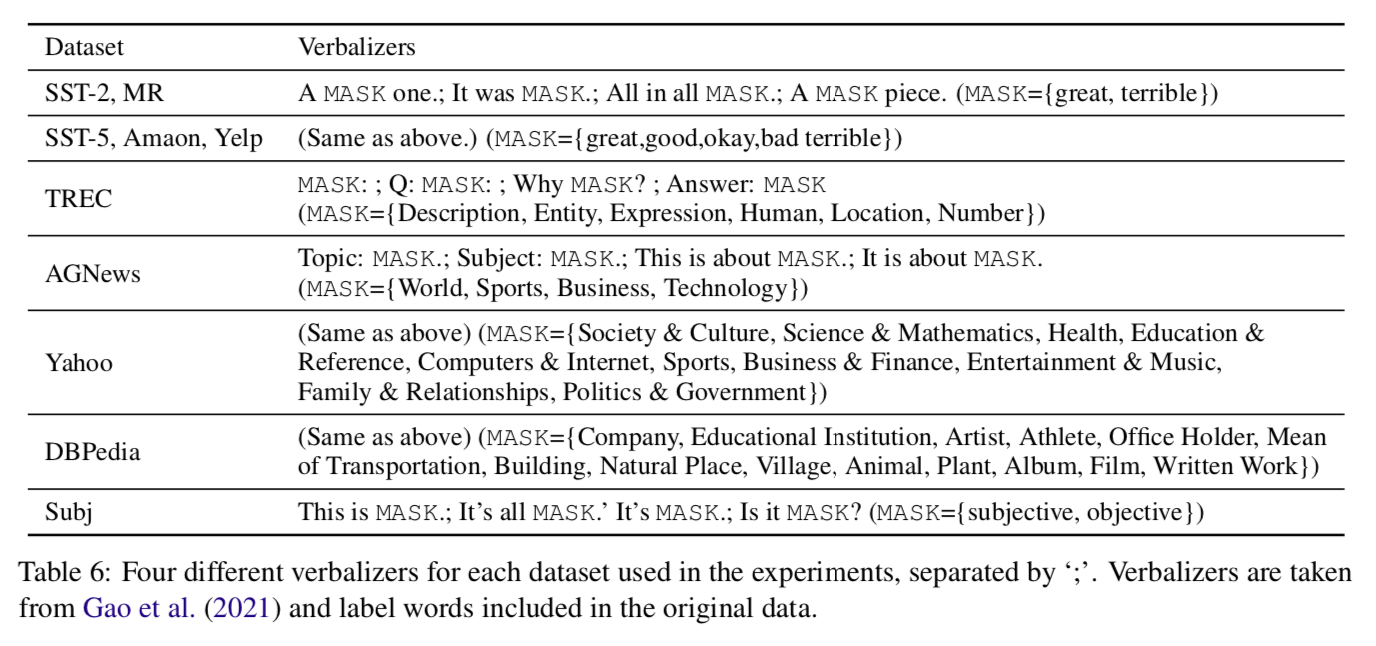
Verbalizers ${v(c_i)}$