Authors: Senci Ying, Yanzhao Zheng, Wuhe Zou
Paper reference: https://aclanthology.org/2021.sdp-1.12.pdf
Contribution
This paper proposes a session based automatic summarization model which uses an ensemble method with both extraction and abstraction based model to generate a long summary for a scientific document.
The results shows that the proposed method can generate sentences with high readability and cover important information of the paper. However, the fluency and coherence of the generated summary is insufficient.
Details
This paper addresses the problem of summarizing scientific documents and generating very long summaries. The paper splits the task into the following steps.
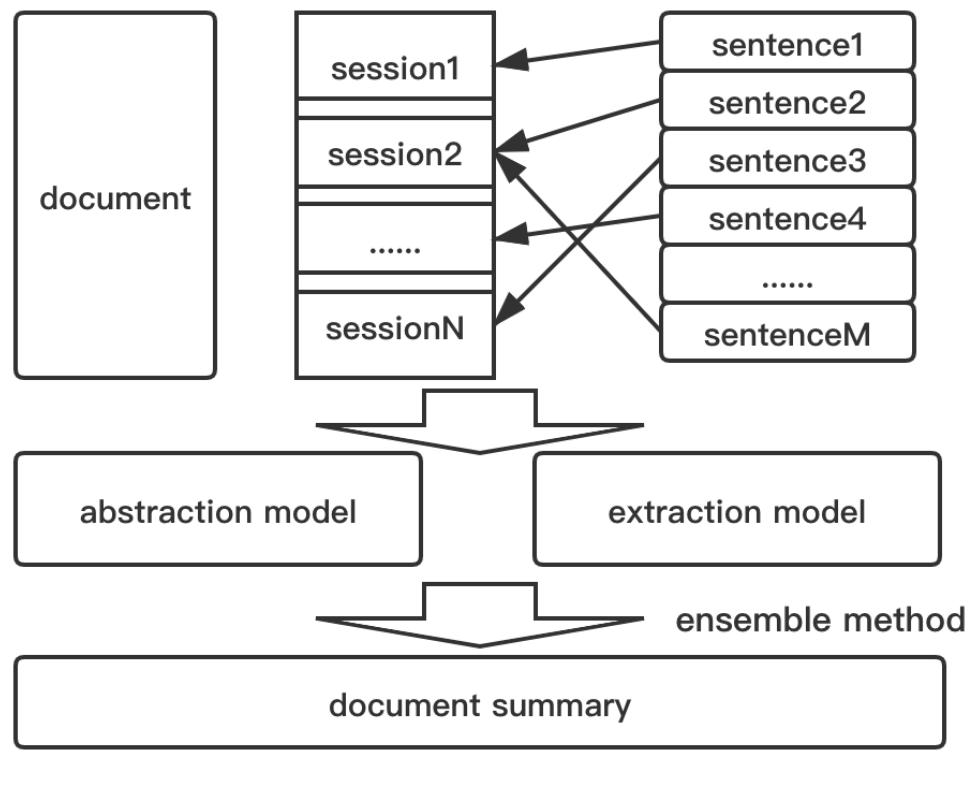
Session generation
First, select the appropriate session size and a buffer (2048 and 128 words in the paper respectively). The buffer is used to keep the last text of the previous session as the context of the current session.
Divide the ground truth summary into sentences, and assign sentences to each session according to the rouge score (continue adding more sentences until rouge score s of added sentences adds up to a certain value). In this way, a new dataset with (session, summary) pair is created.
Generate Summary with Abstraction and extraction based model
This work trains both an abstraction-based and an extraction-based model (list a few in the paper). These two types of model both predict the summary for each session.
Ensemble summaries
The final summary is obtained by merging the summaries of two types of models through the ensemble method:
(1) Drop overlapping summaries between sessions. Summary overlap is defined with certain threshold.
(2) For each session, put abstract summary before extractive summary. Then concatenate the summary from each section.
(3) Filter the combined summaries again by using TextRank algorithm to drop less important sentences.