Authors: Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano\ Paper reference: https://arxiv.org/pdf/2009.01325.pdf
Contribution
The paper shows that it is possible to significantly improve summary quality by training a model to optimize for human preferences (see details). Human feedback models generalize much better to new domains than supervised models. The paper motivates researchers to pay closer attention to how their training loss affects the model behavior they actually want.
Money, Money , and Money.
Details
Misaligned Summarization Models
Summarization models are usually fine-tuned using supervised learning, often to maximize the log probability of a set of human demonstrations. However, there is still a misalignment between this fine-tuning objective—maximizing the likelihood of human-written text—and what we care about—generating high-quality outputs as determined by humans.
Causes of misalignment:
(1) the maximum likelihood objective has no distinction between important errors (e.g. making up facts) and unimportant errors (e.g. selecting the precise word from a set of synonyms);
(2) models are incentivized to place probability mass on all human demonstrations, including those that are low-quality;
(3) distributional shift during sampling can degrade performance; \
Quality can often be improved significantly by non-uniform sampling strategies such as beam search, but these can lead to repetition and other undesirable artifacts. Optimizing for quality may be a principled approach to overcoming these problems.
Methods
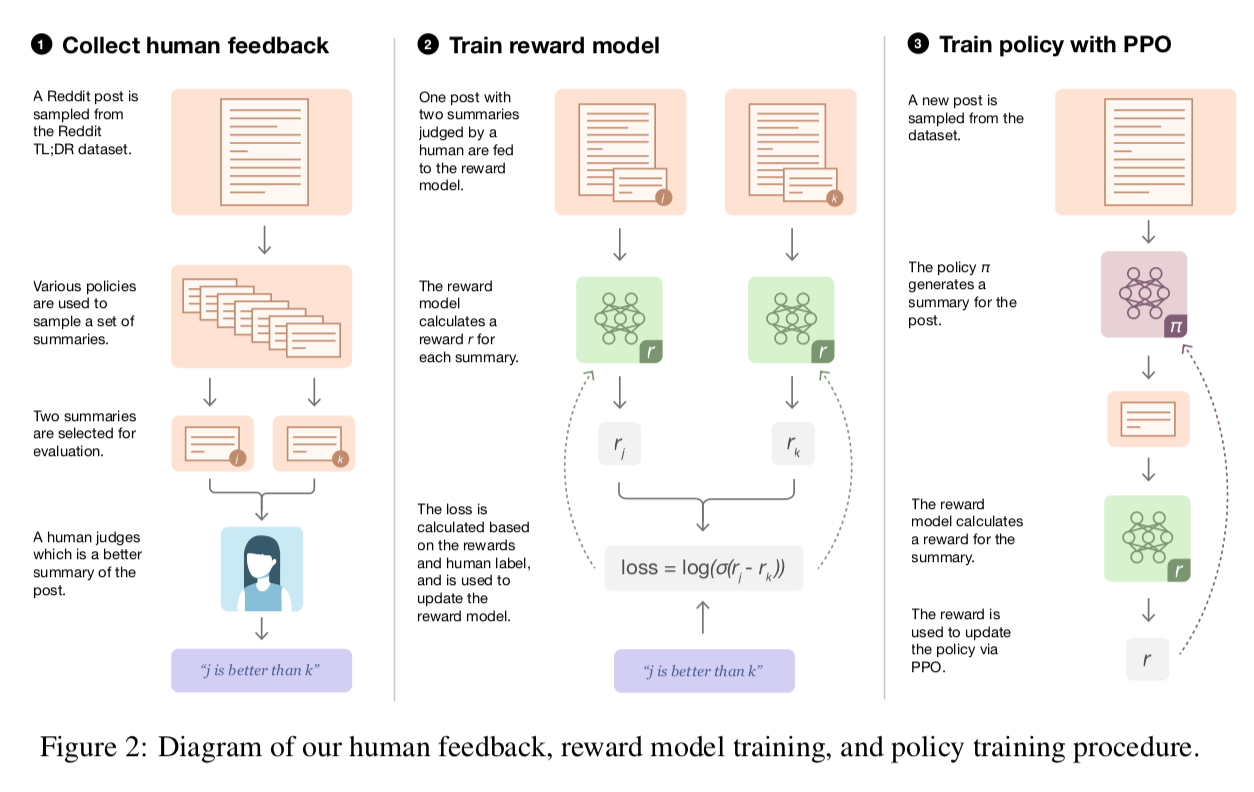
Methods consist of three steps (use the TL;DR Reddit post dataset):
Step 1: Collect samples from existing policies and send comparisons to humans. For each Reddit post, we sample summaries from several sources including the current policy, initial policy, original reference summaries and various baselines. We send a batch of pairs of summaries to our human evaluators, who are tasked with selecting the best summary of a given Reddit post.
Step 2: Learn a reward model from human comparisons. Given a post and a candidate summary, we train a reward model to predict the log odds that this summary is the better one, as judged by our labelers (predict human-preferred summary).
Step 3: Optimize a policy against the reward model. We treat the logit output of the reward model as a reward to fine-tune a summarization policy using reinforcement learning.