Authors: Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Furu Wei
Reference: https://arxiv.org/pdf/2104.08696.pdf
Contribution
This paper proposes a knowledge attribution method to identify the (knowledge) neurons that express facts stored in pretrained Transformers. Specifically, the paper views feed-forward network (i.e., two layer perceptron) modules as knowledge memories in Transformer. The hidden state is fed into the feed-forward network and activates the knowledge neurons (keys). Then the second linear layer outputs the corresponding memory vectors (values).
The paper finds that suppressing and amplifying knowledge neurons can control the expressions of the corresponding knowledge, without effecting other facts, and that knowledge-probing prompts tend to activate knowledge neurons of the specific fact.
It then describes how to leverage knowledge neurons to explicitly edit (update/erase) factual knowledge in Transformers without any fine-tuning.
Details
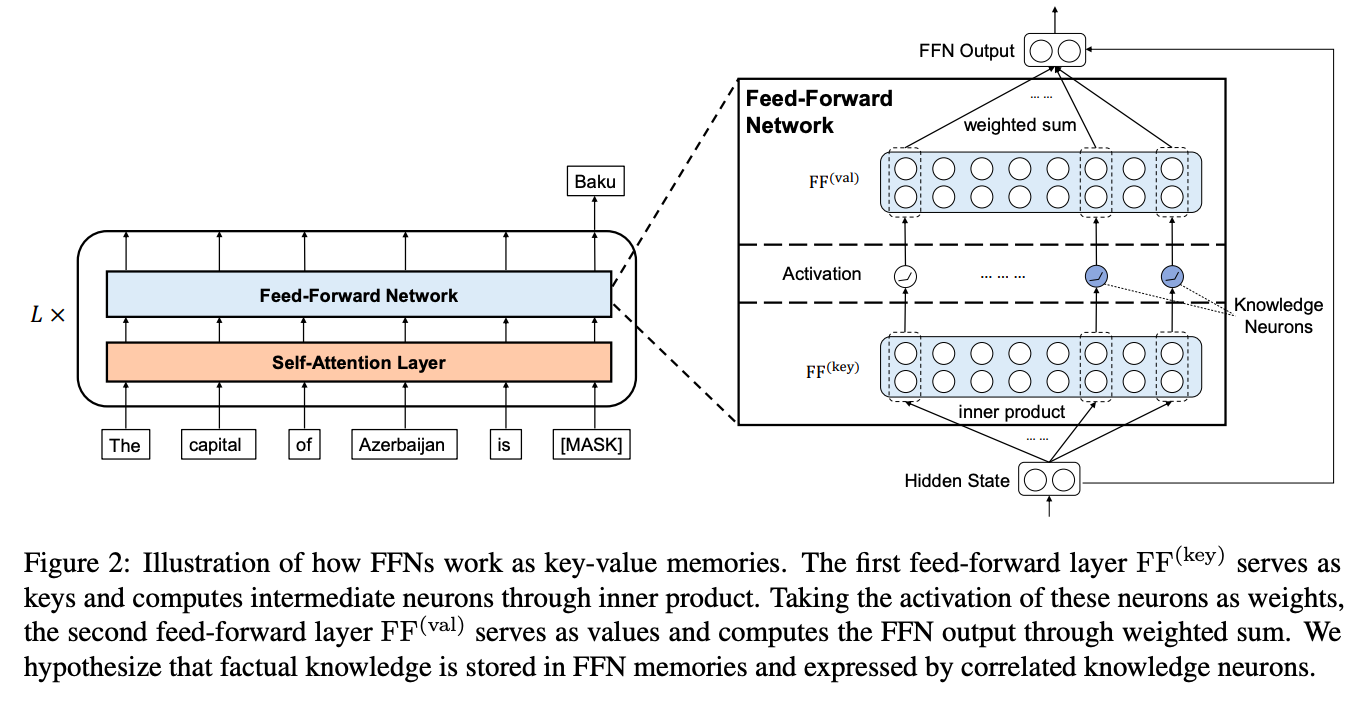
Locating Factual Knowledge
The paper regards FFNs in Transformer as key-value memories, where the first layer serves as keys, the second layer serves as values, and each key-value pair forms a memory slot. Based on this analogy, it hypothesizes that factual knowledge is stored in FFN memories and expressed by the corresponding intermediate neurons, which we call knowledge neurons.
It proposes a knowledge attribution method and a refining strategy to identify knowledge neurons.
Knowledge Assessing Task
Given a triplet $\langle h, r, t\rangle$, the knowledge assessing task requires a pretrained model to answer a cloze-style query $x$ (aka knowledge-probing prompt), which expresses the relational fact but leaves the tail entity as a blank. Then compare the model prediction with ground truth.
Knowledge Attribution

The paper identifies knowledge neurons that contribute the most to the knowledge expression by Integrated Gradients.
With the knowledge attribution method, given a relational fact along with a prompt, we can coarsely locate the factual knowledge to neurons with attribution scores greater than a given threshold. We call these neurons coarse knowledge neurons.
Knowledge Neuron Refining
The main idea is to produce different and diverse prompts expressing the same fact, and then retain neurons shared by many of these prompts.
Use case: Updating/Erasing
Updating Knowledge
Given a relational fact $\langle h, r, t\rangle$ remembered by a pretrained model, we aim to update it to $\left\langle h, r, t^{\prime}\right\rangle$. We directly subtract $\mathbf{t}$ from corresponding value slots (in the second feed forward layer $\mathrm{FF}^{(\text {val})}$ ), and add $\mathbf{t}^{\prime}$ to those value slots, where $\mathbf{t}$ and $\mathbf{t}^{\prime}$ are the word embeddings of $t$ and $t^{\prime}$, respectively.
Erasing Knowledge
Goal: Erase all the relational facts with a specified relation in the model.
First we identify knowledge neurons of all the relational facts. Then, we retain knowledge neurons that belong to at least $m$ relational facts (e.g. $m=5$), and filter out others. Finally, we set the value slots corresponding to these knowledge neurons to the word embedding of $[\mathrm{UNK}]$.
Concern: May influence the expression of other knowledge.