Authors: Yizhe Zhang, Siqi Sun, Xiang Gao, Yuwei Fang, Chris Brockett, Michel Galley, Jianfeng Gao, Bill Dolan
Paper reference: https://arxiv.org/pdf/2105.06597.pdf
Contribution
This paper presents a joint training framework RetGen that trains a document retriever and a multi-document grounded generator in an end-to-end fashion with a language model signal and allows these modules to synergistically cooperate to optimize grounded text generation. Specifically, the document retriever efficiently selects relevant documents and the generator generates text by combining information from retrieved relevant documents and generate a single prediction. This framework alleviates the need for oracle parallel data (prose-document pairs) with which to train a grounded model.
Details
Retrieval Grounded Text Generation
Retrieval grounded text generation aims to predict the upcoming text $y$ that directly follows the existing source prompt (context queries) $x$ ($x, y$ are from a corpus $D$), with access to a document reference set $Z$ (not parallel with $D$).
RetGen
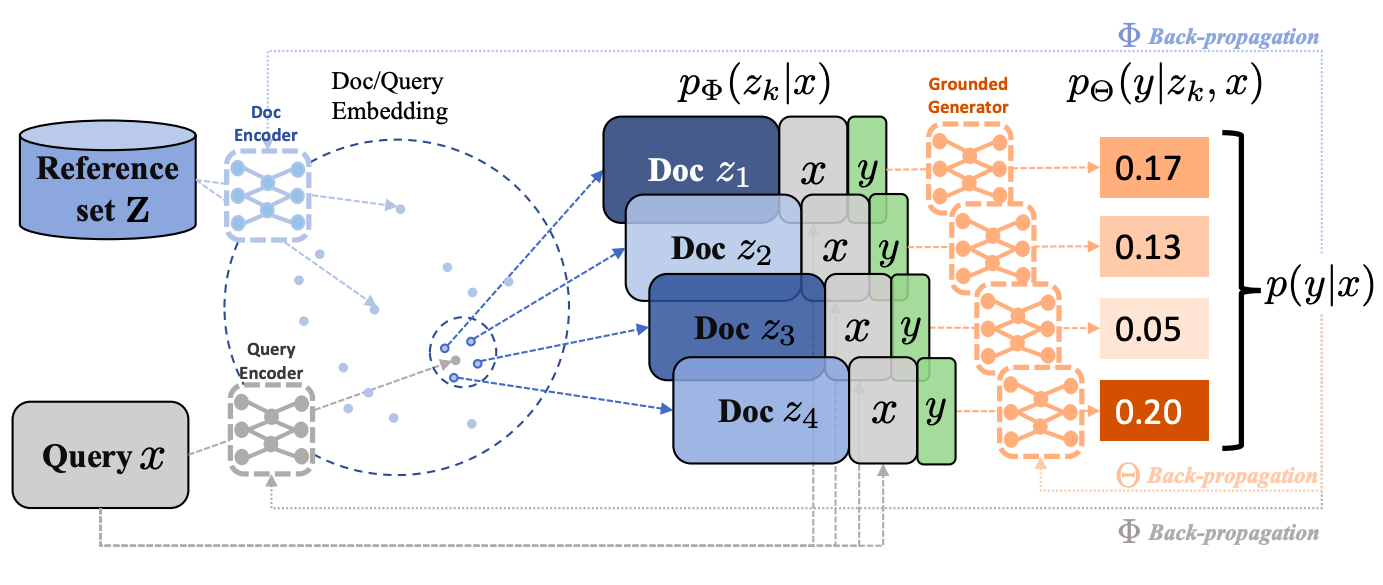
This paper proposes a framework RetGen to solve the Retrieval grounded text generation task. It consists of a dense document retriever and a knowledge-grounded text generator.
Document Retriever
A document retriever (ANCE) narrows down the search for relevant document and accelerate join training with the text generator. Specifically, all documents and context queries are mapped to the same embedding space with separate learnable encoders. A score for each pair is computed by an inner-product, and top $K$ are selected as relevant documents (weight $p(z^{(k)}|x)$ is determined by softmax on scores). Maximum inner product search (MIPS) is employed to reduce searching time.
Refresh Document embeddings
Instead of encoding and refreshing embeddings for all documents after the retriever is updated each time, embeddings for retrieved documents are updated asynchronously after every few hundred steps. Refer to my next post (REALM: Retrieval-Augmented Language Model Pre-Training) for more details.
Retriever Correction
Scores for $(z, x)$ should be updated along generation and consider generated text so far. A correction factor term is derived and can be computed with negligible cost.
Knowledge-Grounded Text Generator
Knowledge grounded text generator (GPT-2/ DialoGPT) takes one document $z$, one context query $x$, and generated text so far as input and the goal is to generate text $y$ following $x$. Maximum Mutual Information (MMI) is employed to encourage the generation to tie better to $z$ and $x$.
Multi-document Decoding
The paper takes Mixture-of-Expert (MoE) approach from a previous work to combines information from retrieved relevant documents and generate a single prediction. Specifically, at each time step, the generator separately generates $K$ output distributions for the next token with same $x$ and generated text so-far but different document $z$. The assemble output is from the weighted distribution based on $p(z^{(k)}|x)$.