Authors: Yumo Xu, Mirella Lapata
Paper reference: https://aclanthology.org/2021.acl-long.475.pdf
Contribution
This paper proposes a weakly supervised framework for abstractive Query Focused Summarization (QFS) under low-resource setting (no query-related resources are required). In particular, the paper introduces a Masked ROUGE Regression framework (MARGE) for evidence sentences estimation and ranking, which relies on a unified representation for summaries and queries. As such, summaries in generic data can be converted into proxy queries for learning a query model.
The proposed framework achieves state-of-the-art results on both evidence ranking and abstractive QFS despite the weakly supervised setting.
Details
Query-Focused Summarization (QFS)
Given a specified query $Q$ and a cluster of documents $D$, the task is to generate a short summary $S$ answering the query. $Q$ often consists of a short title and a query narrative which is longer and more detailed.
Background
Given that ${(D, Q, S)}$ is not readily available, recent work resort to distant supervision from query-relevant NLP resources including question answering. However, queries in QA datasets and QFS are two types of queries and therefore are not identically distributed. Also, it is practically infeasible to find appropriate query-related resources for all domains and topics.
Method
The paper decomposes abstractive QFS into two subtasks:
(1) Query Modeling. Find supportive evidence within a document collection/cluster for a query;
(2) Query Focused Generation. Generate an abstractive summary based on found evidence.
Query Modeling
Overview
The paper trains a query model $q_{\theta}(D| Q ; \theta)$ to estimate whether each sentence in document cluster $D$ is relevant to query $Q$. The paper trains the model on (summary, sentence) pairs via distant supervision derived from generic summarization data ${(D, S)}$ (without $Q$), which is easier to obtain.
Assumptions
- Summaries themselves constitute a response to latent queries.
- Answers to queries can be found in sentences from document cluster $D$.
- If sentences have a high ROUGE score against the reference summary they are likely to contain an answer.
Unified Masked Representation (UMR)
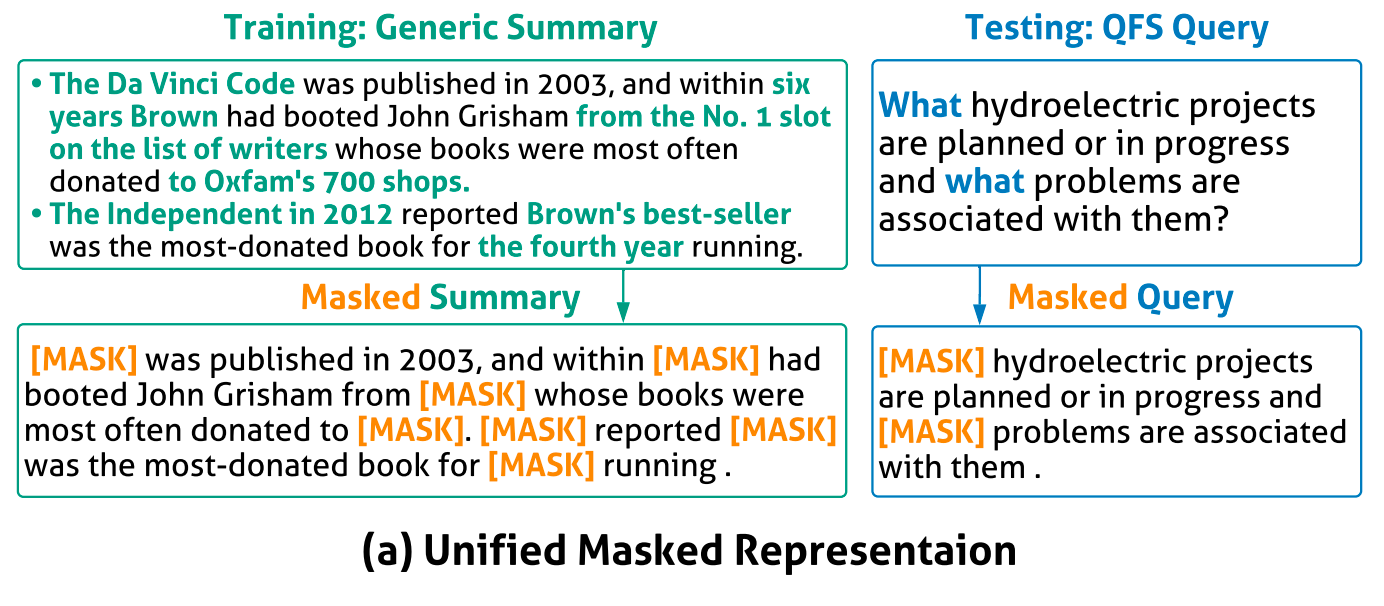
The paper renders queries and summaries in a Unified Masked Representation (UMR) which enables summaries to serve as proxy queries for model training. Therefore, even there are no real query during training, the ground truth summary can indeed be proxy queries to assist training.
UMR for summaries: The UMR for a summary is indeed a summary where some arguments of propositions (using OpenIE) are randomly masked.
UMR for quries: the paper manually collects a small set of query words and mask these words out. For example, how is A , what is B, describe A and tell me B.
The paper uses proxy query $\text{UMR}_S$ during training and an actual query $\text{UMR}_Q$ during inference.
Evidence Ranking
The paper feeds the concatenation of a UMR query and a candidate sentence from document cluster into BERT in the form of “[CLS] $\mathcal{U}$ [SEP] $\mathcal{C}$ [SEP]” to estimates whether the sentence contains sufficient evidence to answer the query.
$\mathcal{U}$ is a sequence of tokens within a UMR query ($\text{UMR}_S$/$\text{UMR}_Q$) and $\mathcal{C}$ a sequence of tokens in a document sentence. The highest ranked sentences are deemed query-relevant and passed on to the summary generation model.
The paper designs a masked ROUGE regression to update BERT during training by using ROUGE as a distant supervision signal.
Query Narrative Expansion
In some cases queries may be relatively short and narratives absent. This can be problematic for the paper’s setup since summary-based query proxies are typically long and detailed. To match the distribution, query narratives are automatically created for short queries in an unsupervised fashion.
Query Focused Generation
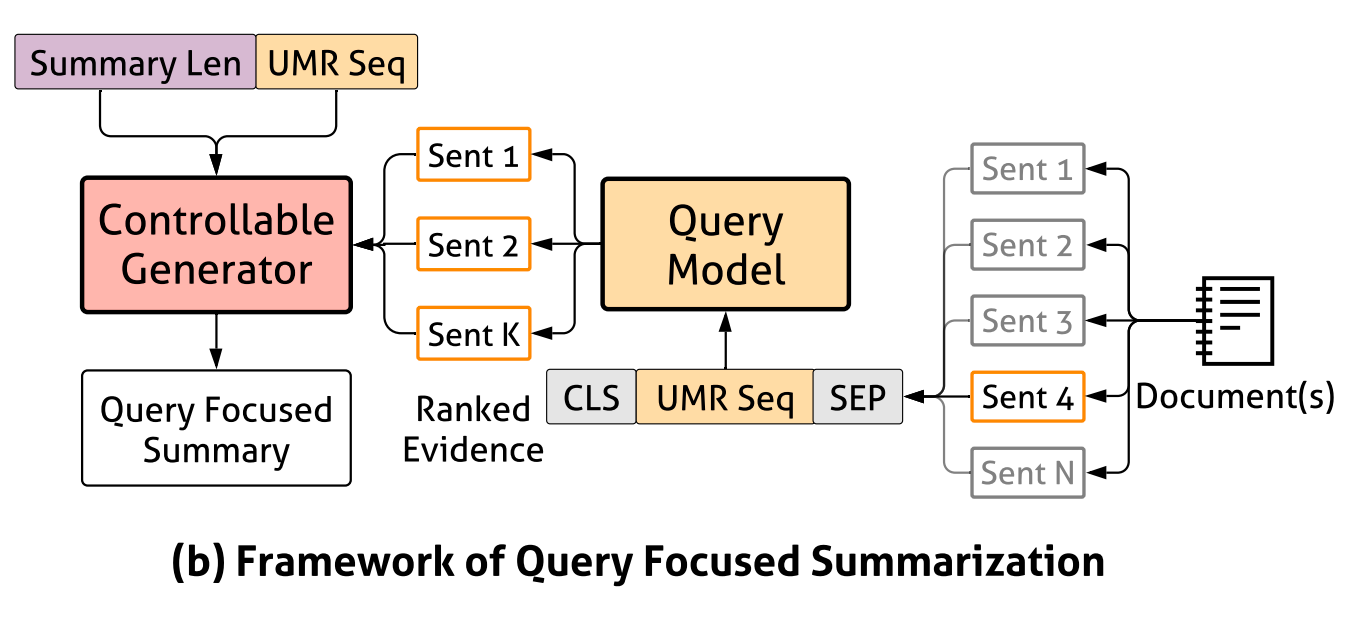
The generation model $p_{\phi}(S | D, Q ; \phi)$ generates query focused abstractive summary $S$ conditioned on evidence provided by the query model and (optionally) the query itself.
Summarization Input
For each instance, all sentences are ranked in descending order according to their ROUGE-2 score against the reference summary. The pretrained language model is fine-tuned against this evidence-ranked list of sentences. During inference, when actual queries are available, top sentences ranked by the query model are used as input to generate.
Summary Length Control
Inform the model the summary length by prepending an expected length token (e.g. [250]) to sentences selected by the evidence ranker.