Authors: Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, Lu Wang
Paper reference: https://aclanthology.org/2021.naacl-main.112.pdf
Contribution
This paper first proposes an efficient encoder-decoder attention with head-wise positional strides (HEPOS), which allows at least doubled input sequence size. HEPOS uses separate encoder-decoder heads on the same layer to cover different subsets of source tokens and all heads collectively attend to the full sequence.
It collects a new large-scale dataset GOVREPORT, which has significantly longer documents and summaries and salient content is spread throughout the documents.
The paper also proposes a new QA based evaluation metric for faithfulness. It is shown to be better correlated with human judgment.
Details
Existing efficient self-attentions
The paper lists some representative and efficient self-attention encoder variants that can build on BART.
Fixed Patterns:
- Sliding window attentions (Beltagy et al., 2020).
- Adaptive span (Sukhbaatar et al. 2019).
- Global tokens (Beltagy et al., 2020).
- Stride patterns (Child et al. 2019).
- Random attention (motivated by Zaheer et al., 2020).
Low-rank Methods:
- Linformer (Wang et al. 2020), it can be encoder or adapted for encoder-decoder attentions.
Learnable Patterns:
- Locality-sensitive hashing (LSH) attentions (Kitaev et al., 2020).
- Sinkhorn attentions (Tay et al., 2020a).
Among all encoder variants, learnable patterns perform the best, approaching the performance of full attentions.
Encoder-decoder Attention with Head-wise Positional Strides (HEPOS)
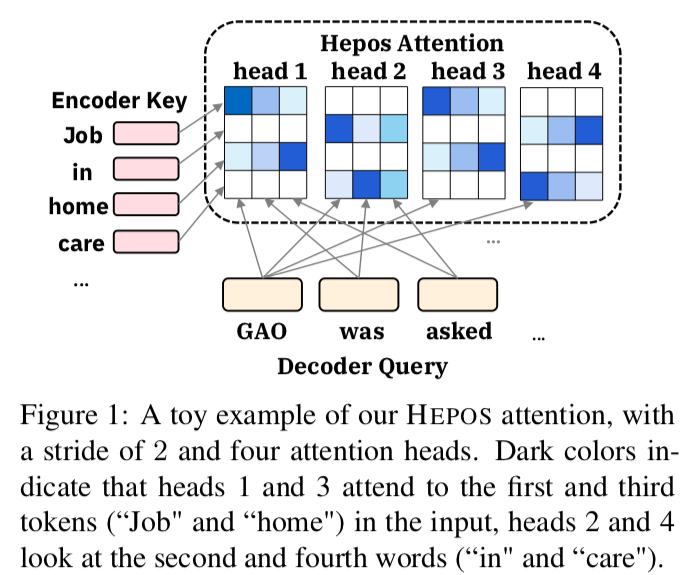
HEPOS allows models to consume longer sequences and it is based on two observations: (1) Attention heads are redundant; (2) Any individual head rarely attends to several tokens in a row.
HEPOS is capable of both identifying the salient content and capturing the global context. Human judges rate the summaries generated using HEPOS to be more informative and faithful.
Comparing to truncation, models that read more text obtain higher ROUGE scores and the generated summaries are more faithful and informative.