Authors: Jiacheng Xu, Greg Durrett
Paper reference: https://aclanthology.org/2021.acl-long.539.pdf
Contribution
This paper proposes a two-stage framework for interpreting the stepwise decisions of a summarization model and attributing generation decisions to the input document. In particular, it conducts an ablation study to determine the generation mode at each decoding step; and experiments with attribution methods to see if highlighted attributions are truly important for the generation of the next token.
The paper further presents a Sentence Fusion case study to demonstrate the potential use of the proposed method for fine-grained factuality evaluation.
Details
Stage I - Ablation: Mapping Model Behavior
The ablation study compares the predictions of different model and input configurations. The goal is to coarsely determine the mode of generation (discuss below).
Ablation Models
This paper probes the model by predicting next words with various model ablations:
(1) LM$\mathbf{_\emptyset}$. A basic BART model with no input;
(2) S$\mathbf{_\emptyset}$. A BART summarization model with no input;
(3) S$\mathbf{_{part}}$. A BART summarization model with part of the document as input;
(4) S$\mathbf{_{full}}$. A BART summarization model with the full document as input.
These ablations tell when the stepwise prediction is context-independent or context-dependent.
Distance Metric
The paper uses the L1 norm to measure the distance of two distributions over tokens for each timestep.
Generation Mode and Existing Memorization/Bias
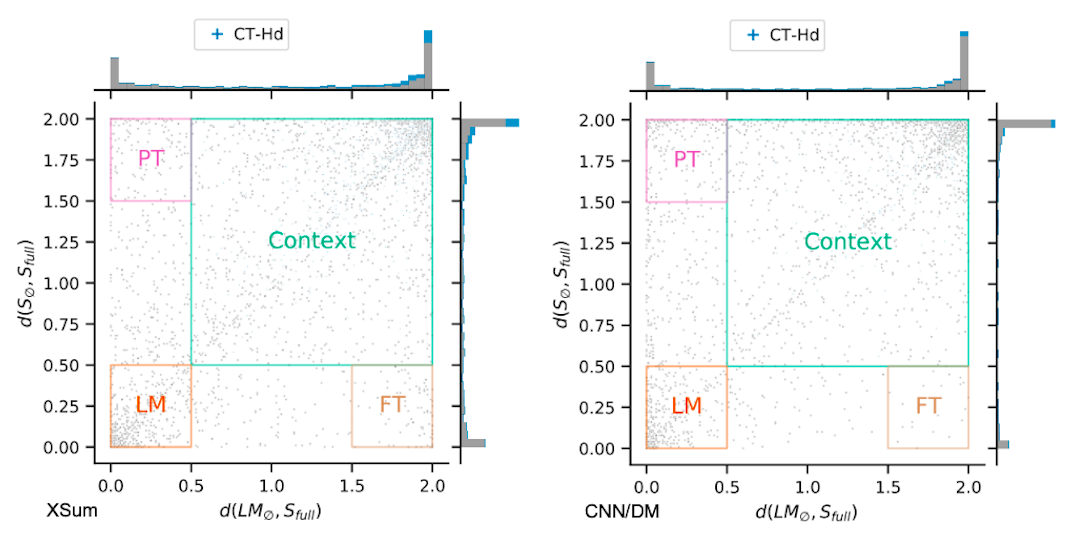
LM (lower left): decisions that can be easily made by using only decoder information, even without training or knowledge of the input document.
CTX (upper right): cases where the input is needed to make the prediction.
FT (lower right): cases where the finetuned decoder-only model is a close match but the pre-trained model is not. This reflects memorization of training summaries/ bias from fine-tuning training summaries.
PT (upper left): cases where LM$\mathbf{_\emptyset}$ agrees with S$\mathbf{_{full}}$ but S$\mathbf{_\emptyset}$ does not; that is, finetuning a decoder-only model causes it to work less well. This reflects memorization of data (bias) from the pre-training corpus (prior knowledge).
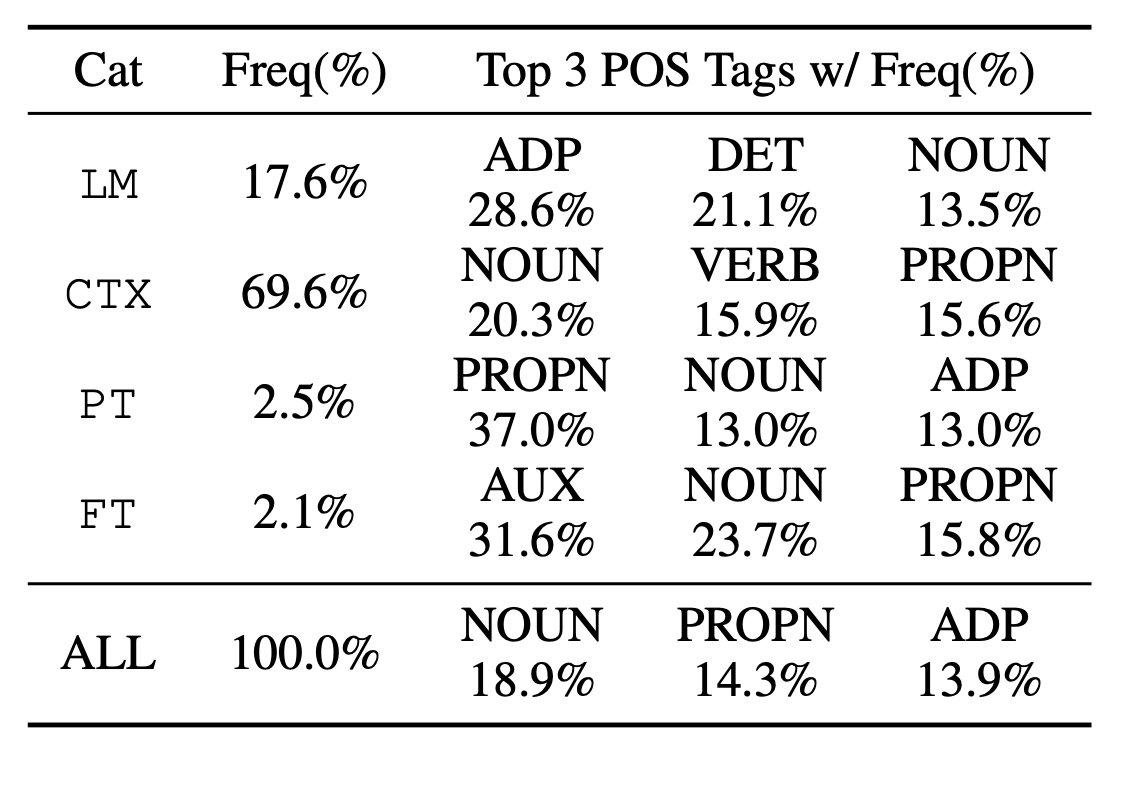
POS Tags Distribution over regions
Here is the top three POS tags of generated words for each region in XSum and the percentage of examples falling into each region. More than two thirds of generation steps actually do rely heavily on the context.
Stage II - Attribution
The paper explores interpreting stepwise decisions that rely on the context using several different attribution methods. The goal is to see whether highlighted attributions are truly important for the generation of the next token.
Experiements show that Integrated Gradient and Input Gradient are the best techniques to select content and reconstruct the model’s predicted token from perturbations of the input.