Authors: Jiacheng Xu, Zhe Gan, Yu Cheng, Jingjing Liu
Paper reference: https://aclanthology.org/2020.acl-main.451.pdf
Contribution
This paper proposes a discourse-aware extractive summarization model, DiscoBERT, which operates on a sub-sentential discourse unit level to perform compression with extraction simultaneously and reduce redundancy across sentences. It proposes two discourse-oriented graphs (RST Graph and Coreference Graph) as inductive bias to capture long-range dependencies among discourse units.
Details
Discourse Analysis
In the Rhetorical Structure Theory (RST) framework, the discourse structure of text can be represented in a tree format. The whole document can be segmented into contiguous, adjacent and non-overlapping text spans called Elementary Discourse Units (EDUs). Each EDU is tagged as either Nucleus or Satellite, which characterizes its nuclearity or saliency. Nucleus nodes are generally more central, and Satellite nodes are more peripheral and less important in terms of content and grammatical reliance.
RST Graph
RST Graph aims to provide both local paragraph-level and long-range document-level connections among EDUs
Coreference Graph
For each coreference cluster, all the discourse units containing the mention of the same cluster will be connected. This process is iterated over all the coreference mention clusters to create the final Coreference Graph.
Model
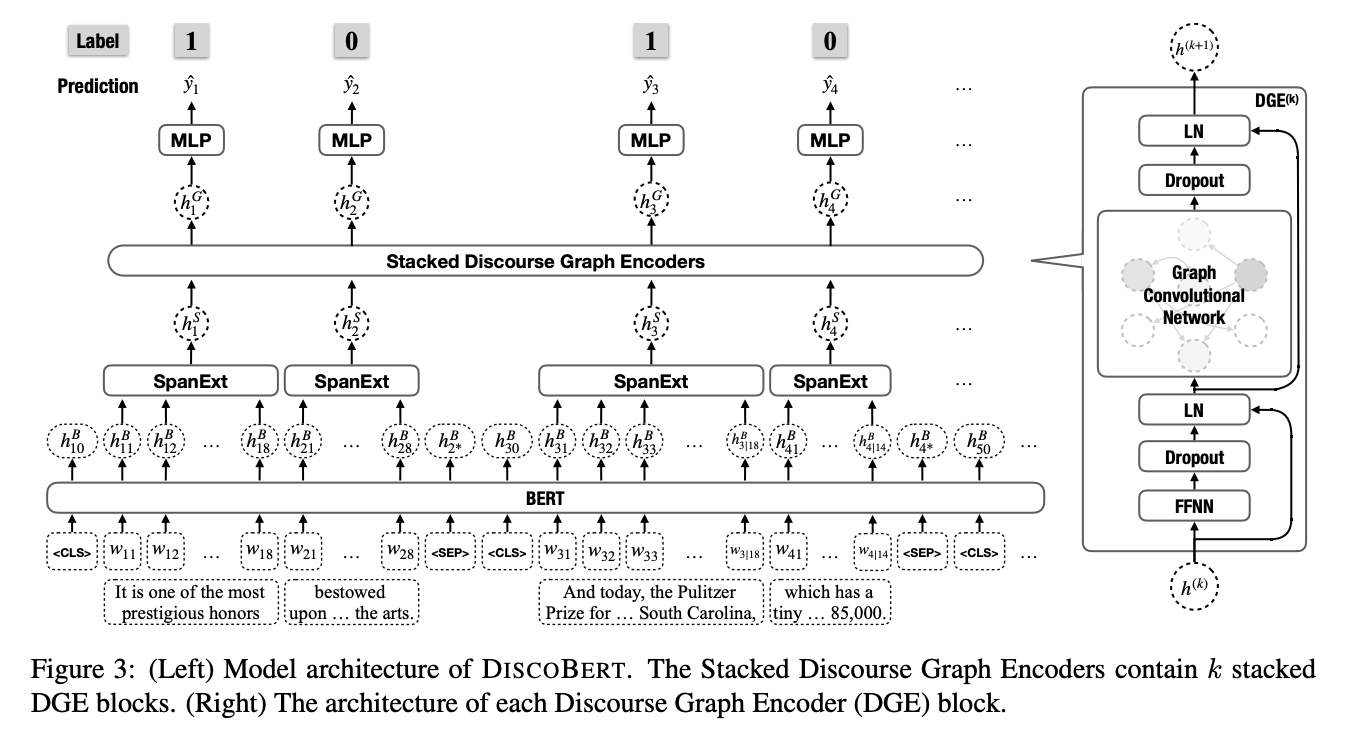
The paper formulates the extractive summarization as a sequential labeling task, where each EDU is scored by neural networks, and decisions are made based on the scores of all EDUs. The creation of oracle labels is operated on EDU level. The paper greedily picks up EDUs with their necessary dependencies until R-1 F1 drops.
Steps:
(1) A pretrained BERT model is first used to encode the whole document on the token level;
(2) A self-attentive span extractor is used to obtain the EDU representations from the corresponding text spans (EDU);
(3) The Graph Encoder takes the output of the Document Encoder as input and updates the EDU representations with Graph Convolutional Network based on the constructed discourse graphs;
(4) Predict the oracle labels based on updated EDU representations.