Authors: Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, Yannis Kalantidis
Paper reference: https://arxiv.org/pdf/1910.09217.pdf
Introduction
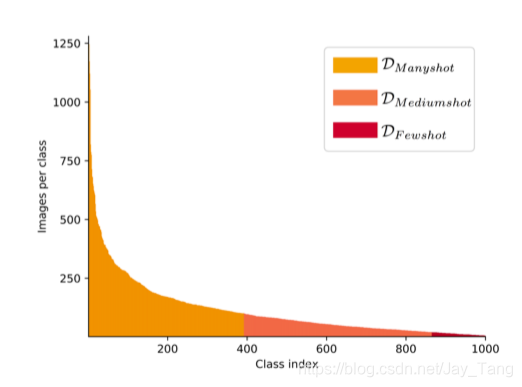
When learning with long-tailed data, a common challenge is that instance-rich (or head) classes dominate the training procedure. The learned classification model tends to perform better on these classes, while performance is significantly worse for instance-scarce (or tail) classes (under-fitting).
The general scheme for long-tailed recognition is: classifiers are either learned jointly with the representations end-to-end, or via a two-stage approach where the classifier and the representation are jointly fine-tuned with variants of class-balanced sampling as a second stage.
In our work, we argue for decoupling representation and classification. We demonstrate that in a long-tailed scenario, this separation allows straightforward approaches to achieve high recognition performance, without the need for designing sampling strategies, balance-aware losses or adding memory modules.
Recent Directions
Recent studies' directions on solving long-tailed recognition problem:
- Data distribution re-balancing. Re-sample the dataset to achieve a more balanced data distribution. These methods include over-sampling, down-sampling and class-balanced sampling.
- Class-balanced Losses. Assign different losses to different training samples for each class.
- Transfer learning from head- to tail classes. Transfer features learned from head classes with abundant training instances to under-represented tail classes. However it is usually a non-trivial task to design specific modules for feature transfer.
Sampling Strategies
For most sampling strategies presented below, the probability $p_j$ of sampling a data point from class $j$ is given by: $$ p_{j}=\frac{n_{j}^{q}}{\sum_{i=1}^{C} n_{i}^{q}} $$ where $q \in[0,1]$, $n_j$ denote the number of training sample for class $j$ and $C$ is the number of training classes. Different sampling strategies arise for different values of $q$ and below we present strategies that correspond to $q=1, q=0,$ and $q=1 / 2$.
- Instance-balanced Sampling. This is the most common way of sampling data, where each training example has equal probability of being selected. Here $q=1$. For imbalanced datasets, instance-balanced sampling has been shown to be sub-optimal as the model under-fits for few-shot classes leading to lower accuracy, especially for balanced test sets.
- Class-balanced Sampling. Class-balanced sampling has been used to alleviate the drawback of Instance-balanced Sampling, as each class has an equal probability of being selected.
- Square-root sampling. Set $q = 1/2$.
- Progressively-balanced sampling. Combinations of the sampling strategies presented above. In practice this involves first using instance-balanced sampling for a number of epochs, and then class-balanced sampling for the last epochs. Here, we experiment with a softer version, that progressively “interpolates” between instance-balanced and class-balanced sampling as learning progresses class $j$ is now a function of the epoch $t,$ $$p_{j}^{\mathrm{PB}}(t)=\left(1-\frac{t}{T}\right) p_{j}^{\mathrm{IB}}+\frac{t}{T} p_{j}^{\mathrm{CB}} $$ where $T$ is the total number of epochs.
Methods of Learning Classifiers
Classifier Re-training (cRT)
Re-train the classifier with class-balanced sampling. That is, keeping the representations fixed, we randomly re-initialize and optimize the classifier weights $W$ and $b$ for a small number of epochs using class-balanced sampling.
Nearest Class Mean classifier (NCM)
First compute the mean feature representation for each class on the training set and then perform nearest neighbor search either using cosine similarity or the Euclidean distance computed on L2 normalized mean features. (the cosine similarity alleviates the weight imbalance problem via its inherent normalization)
$\tau$-normalized classifier $(\tau$-normalized)
We investigate an efficient approach to re-balance the decision boundaries of classifiers, inspired by an empirical observation:
Empirical Observation: after joint training with instance-balanced sampling, the norms of the weights $\left|w_{j}\right|$ are correlated with the cardinality of the classes $n_j$, while, after fine-tuning the classifiers using class-balanced sampling, the norms of the classifier weights tend to be more similar.
Inspired by the above observations, we consider rectifying imbalance of decision boundaries by adjusting the classifier weight norms directly through the following $\tau$-normalization procedure. Formally, let $\boldsymbol{W} = {w_{j}} \in \mathbb{R}^{d \times C},$ where $w_{j} \in \mathbb{R}^{d}$ are the classifier weights corresponding to class $j .$ We scale the weights of $\boldsymbol{W}$ to get $\widetilde{\boldsymbol{W}}= {\widetilde{w_{j}} }$ by: $$ \widetilde{w_{i}}=\frac{w_{i}}{\left|w_{i}\right|^{\tau}} $$ where $\tau$ is a hyper-parameter controlling the “temperature” of the normalization, and $|\cdot|$ denotes the $L_{2}$ norm. When $\tau=1$, it reduces to standard $L_{2}$ -normalization. When $\tau=0$, no scaling is imposed. We empirically choose $\tau \in(0,1)$ such that the weights can be rectified smoothly.
Learnable weight scaling (LWS). Another way of interpreting $\tau$-normalization would be to think of it as a re-scaling of the magnitude for each classifier $w_{i}$ keeping the direction unchanged. This could be written as $$ \widetilde{w_{i}}=f_{i} * w_{i}, \text { where } f_{i}=\frac{1}{\left|w_{i}\right|^{\tau}} $$ Although for $\tau$-normalized in general $\tau$ is chosen through cross-validation.
Note: NCM and $\tau$-normalized cases give competitive performance even though they are free of additional training and involve no additional sampling procedure.
Experiments
We perform extensive experiments on three large-scale long-tailed datasets.
Datasets
- Places-LT. Artificially truncated from the balanced version. Places-LT contains images from 365 categories and the number of images per class ranges from 4980 to 5.
- ImageNet-LT. Artificially truncated from the balanced version. ImageNet-LT has 1000 classes and the number of images per class ranges from 1280 to 5 images.
- iNaturalist 2018. iNaturalist 2018 is a real-world, naturally long-tailed dataset, consisting of samples from 8,142 species.
Evaluation Protocol
To better examine performance variations across classes with different number of examples seen during training, we report accuracy on three splits of the set of classes: Many-shot (more than 100 images), Medium-shot (20∼100 images) and Few-shot (less than 20 images).
This figure compares different sampling strategies for the conventional joint training scheme to a number of variations of the decoupled learning scheme on the ImageNet-LT dataset.

Results
Sampling matters when training jointly
- For Joint Learning, we see consistent gains in performance when using better sampling strategies.
- The trends are consistent for the overall performance as well as the medium- and few- shot classes, with progressively-balanced sampling giving the best results.
- Instance-balanced sampling gives the highest performance for the many-shot classes. This is well expected since the resulted model is highly skewed to the many-shot classes.
Instance-balanced sampling generalize well
Among all decoupled methods, we see that Instance-balanced sampling gives the best results. This is particularly interesting, as it implies that data imbalance might not be an issue learning high-quality representations.
Decoupled Learning strategy helps
- For most cases, performance using decoupled methods is significantly better in terms of overall performance, as well as all splits apart from the many-shot case.
To further justify our claim that it is beneficial to decouple representation and classifier, we experiment with fine-tuning the backbone network (ResNeXt-50) jointly with the linear classifier. Here is the result:
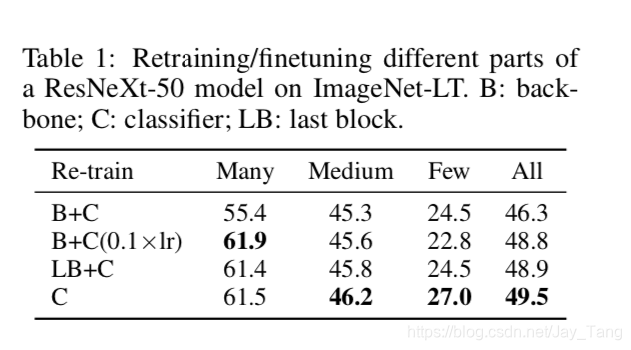
Fine-tuning the whole network yields the worst performance, while keeping the representation frozen performs best. This result suggests that decoupling representation and classifier is desirable for long-tailed recognition.
Weight Norm Visualization
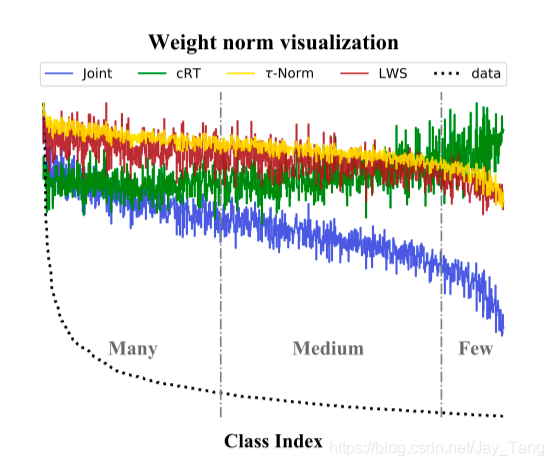
This figure shows L2 norms of the weight vectors for all classifiers, as well as the training data distribution sorted in a descending manner with respect to the number of instances in the training set.
Compare to SOTA
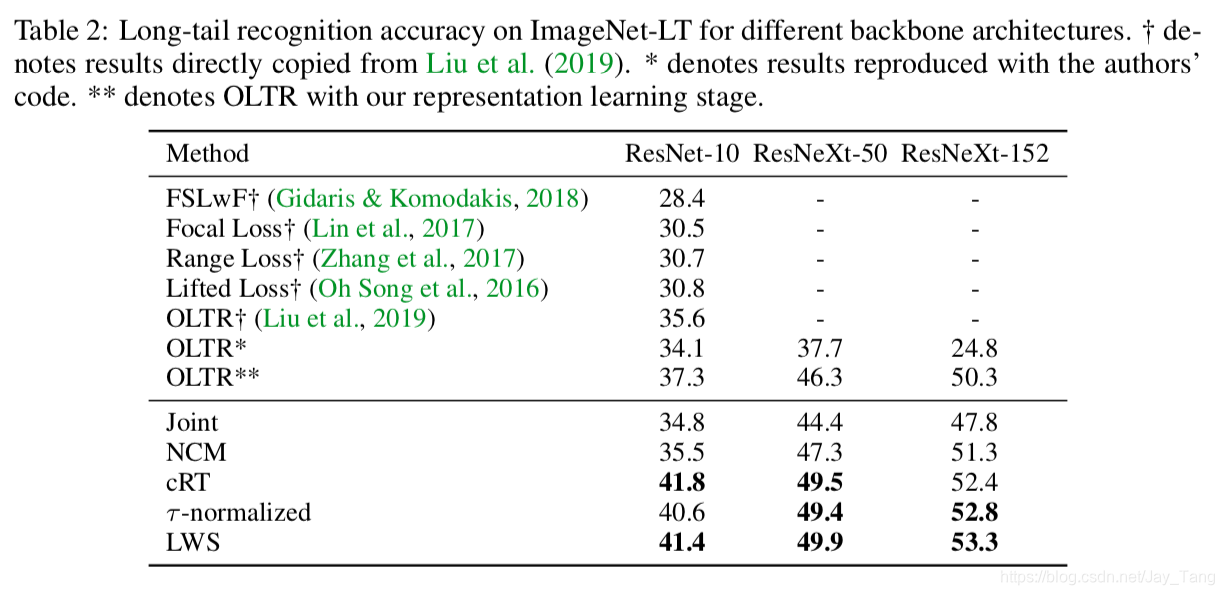
We compare the performance of the decoupled schemes to other recent works that report state-of-the-art results on on three common long-tailed benchmarks. This is the result for ImageNet-LT.
Contributions
- Instance-balanced sampling gives more generalizable representations that can achieve state-of-the-art performance after properly re-balancing the classifiers and without need of carefully designed losses or memory units.
- It is advantageous in long-tailed recognition to re-adjust the decision boundaries specified by the jointly learned classifier during representation learning (NCM, cRT, $\tau$-normalized).
- By applying the decoupled learning scheme to standard networks, we achieve significantly higher accuracy than well established state-of-the-art methods on multiple long- tailed recognition benchmark datasets.
Reference:
- Decoupling Representation and Classifier for Long-Tailed Recognition. https://arxiv.org/abs/1910.09217.