Authors: Fenia Christopoulou, Makoto Miwa, Sophia Ananiadou
Paper reference: https://arxiv.org/pdf/1909.00228.pdf
Relation Extraction (RE)
Relation Extraction (RE): The extraction of relations between named entities in text.

Relation Extraction is an important task of NLP. Most existing works focus on intra-sentence RE. In fact, in real-world scenarios, a large amount of relations are expressed across sentences. The task of identifying these relations is named inter-sentence RE.
Typically, inter-sentence relations occur in textual snippets with several sentences, such as documents. In these snippets, each entity is usually repeated with the same phrases or aliases, the occurrences of which are often named entity mentions and regarded as instances of the entity.
The multiple mentions of the target entities in different sentences can be useful for the identification of inter-sentential relations, as these relations may depend on the interactions of their mentions with other entities in the same document. The figure above is an good example of identifying the relationship between “ethambutol”, “isoniazid” and “scotoma”, where they all interact with the green colored entity (and its alias).
document-level RE
-
In concept, document-level RE the input is considered an annotated document. The annotations include concept-level entities as well as multiple occurrences of each entity under the same phrase of alias, i.e., entity mentions.
-
Objective: the objective of the task is given an annotated document, to identify all the related concept-level pairs in that document.
Document-level RE is not common in the general domain, as the entity types of interest can often be found in the same sentence. On the contrary, in the biomedical domain, document-level relations are particularly important given the numerous aliases that biomedical entities can have (as shown in the figure above).
Intuition
Graph-based neural approaches have proven useful in encoding long distance, inter-sentential information. These models interpret words as nodes and connections between them as edges. They typically perform on the nodes by updating the representations during training.
This paper: However, a relation between two entities depends on different contexts. It could thus be better expressed with an edge connection that is unique for the pair. A straightforward way to address this is to create graph-based models that rely on edge representations rather focusing on node representations, which are shared between multiple entity pairs.
Contribution
- We propose a novel edge-oriented graph neural model for document-level relation extraction, which encodes information into edge representations rather than node representations.
- Analysis indicates that the document-level graph can effectively encode document-level dependencies.
- we show that inter-sentence associations can be beneficial for the detection of intra-sentence relations.
Overview of Proposed Model
We presented a novel edge-oriented graph neural model (EoG) for document-level relation extraction using multi-instance learning. The proposed model constructs a document-level graph with heterogeneous types of nodes and edges, modelling intra- and inter-sentence pairs simultaneously with an iterative algorithm over the graph edges.
Here is an illustration of the abstract architecture of the proposed approach.

Proposed Model
The proposed model consists of four layers: sentence encoding, graph construction, inference and classification layers. The model receives a document (with identified concept-level entities and their textual mentions) and encodes each sentence separately. A document-level graph is constructed and fed into an iterative algorithm to generate edge representations between the target entity nodes.
Sentence Encoding Layer
We use a Bi-LSTM to encode each sentence and then get a contextualized word representations of the input sentence. The contextualized word representations from the encoder are then used to construct a document-level graph structure.
Graph construction Layer
Graph construction consists of Node Construction and Edge Construction.
Node Construction
They form three distinct types of nodes in the graph:
- Mention nodes (M) $n_m$. Mention nodes correspond to different mentions of entities in the input document. The representation of a mention node is formed as the average of the words ($w$) that the mention contains, i.e. $\operatorname{avg}{w{i} \in m}\left(\mathbf{w}_{i}\right)$.
- Entity nodes (E) $n_e$. Entity nodes represent unique entity concepts. The representation of an entity node is computed as the average of the mention ($m$) representations associated with the entity, i.e. $\operatorname{avg}{m{i} \in e}\left(\mathbf{m}_{i}\right)$.
- Sentence nodes (S) $n_s$. Sentence nodes correspond to sentences. A sentence node is represented as the average of the word representations in the sentence, i.e. $\operatorname{avg}{w{i} \in s}\left(\mathbf{w}_{i}\right)$.
To distinguish different node types in the graph, they concatenate a node type ($t$) embedding to each node representation. The final node representations are then estimated as $\mathbf{n}{m}=[\operatorname{avg}{w_{i} \in m}\left(\mathbf{w}{i}\right) ; \mathbf{t}{m}], \mathbf{n}{e}=$ $[\operatorname{avg}{m_{i} \in e}\left(\mathbf{m}{i}\right) ; \mathbf{t}{e}], \mathbf{n}{s}=[\operatorname{avg}{w_{i} \in s}\left(\mathbf{w}{i}\right) ; \mathbf{t}{s}]$.
Edge Construction
We pre-define the following edge types:
-
Mention-Mention (MM): Mention-to-mention edges are connected if the corresponding mentions reside in the same sentence. The edge representation between each mention pair $m_{i}$ and $m_{j}$ is generated by concatenating the representations of the nodes, the contexts $c_{m_{i}, m_{j}}$ and a distance embedding associated with the distance between the two mentions $d_{m_{i}, m_{j}},$ in terms of intermediate words: $\mathbf{x}{\mathbf{M M}} = [\mathbf{n}{m_{i}} ; \mathbf{n}{m{j}} ; \mathbf{c}{m{i}, m_{j}} ; \mathbf{d}{m{i}, m_{j}}]$, the context is calculated using $$\begin{aligned} k &\in {1,2}\ \alpha_{k, i} &=\mathbf{n}{m{k}}^{\top} \mathbf{w}{i} \ \mathrm{a}{k, i} &=\frac{\exp \left(\alpha_{k, i}\right)}{\sum_{j \in[1, n], j \notin m_{k}} \exp \left(\alpha_{k, j}\right)} \ \mathrm{a}{i} &=\left(\mathrm{a}{1, i}+\mathrm{a}{2, i}\right) / 2 \ \mathrm{c}{m_{1}, m_{2}} &=\mathbf{H}^{\top} \mathrm{a} \end{aligned}$$ where $\mathbf{H} \in \mathbb{R}^{w \times d}$ is a sentence word representations matrix.
-
Mention-Sentence (MS): Mention-to-sentence nodes are connected if the mention is in the sentence. The initial edge representation is represented as $\mathbf{x}{\mathbf{MS}} = [\mathbf{n}{m} ; \mathbf{n}_{s}]$.
-
Mention-Entity (ME): Mention-to-entity nodes are connected if the mention is associated with the entity, $\mathbf{x}{\mathbf{ME}} = [\mathbf{n}{m} ; \mathbf{n}_{e}]$.
-
Sentence-Sentence (SS): To encode the distance between sentences, they concatenate to the sentence node representations their distance in the form of an embedding. They connect all sentence nodes in the graph, $\mathbf{x}{\mathbf{MS}} = [\mathbf{n}{s_i} ; \mathbf{n}{s_j}; \mathbf{d}{s_i,s_j}]$.
-
Entity-Sentence (ES): Entity-to-sentence nodes are connected if at least one mention of the entity is in this sentence, $\mathbf{x}{\mathbf{ES}} = [\mathbf{n}{e} ; \mathbf{n}_{s}]$.
Then there is a linear transformation to make sure each edge representation has the same dimension. For different edge representations, the dimension of the linear transformation layer is different: $$\mathbf{e}{z}^{(1)}=\mathbf{W}{z} \mathbf{x}{z}$$ where $\mathbf{e}{z}^{(1)}$ is an edge representation of length 1. $\mathbf{W}{z} \in \mathbb{R}^{d{z} \times d}$ corresponds to a learned matrix and $z \in[\mathrm{MM}, \mathrm{MS}, \mathrm{ME}, \mathrm{SS}, \mathrm{ES}]$.
Inference Layer
Note that entity-to-entity (EE) edge is not pre-defined in the previous step. We can only generate EE edge representations by representing a path between their nodes. we adapt two-step inference mechanism to encode interactions between nodes and edges in the graph and hence model EE associations.
First Step
Goal: generate a path between two nodes $i$ and $j$ using intermediate nodes $k$ (Intermediate nodes without adjacent edges to the target nodes are ignored).
We thus combine the representations of two consecutive edges $e_{ik}$ and $e_{kj}$, using a modified bilinear transformation. This action generates an edge representation of double length. We combine all existing paths between $i$ and $j$ through $k$:
$$f\left(\mathbf{e}{i k}^{(l)}, \mathbf{e}{k j}^{(l)}\right)=\sigma\left(\mathbf{e}{i k}^{(l)} \odot\left(\mathbf{W} \mathbf{e}{k j}^{(l)}\right)\right)$$ where $\mathbf{W} \in$ $\mathbb{R}^{d_{z} \times d_{z}}$ is a learned parameter matrix, $\odot$ refers to element-wise multiplication, $l$ is the length of the edge and $\mathbf{e}_{i k}$ corresponds to the representation of the edge between nodes $i$ and $k$.
Second Step
During the second step, we aggregate the original (short) edge representation and the new (longer) edge representation resulted from Equation (3) as follows:$$ \mathbf{e}{i j}^{(2 l)}=\beta \mathbf{e}{i j}^{(l)}+(1-\beta) \sum_{k \neq i, j} f\left(\mathbf{e}{i k}^{(l)}, \mathbf{e}{k j}^{(l)}\right)$$ where $\beta \in[0,1]$.
The two steps are repeated a finite number of times N.
- Everytime when going through step one, we find an intermediate node. With initial edge length equal to 1, the first iteration results in edges of length up-to 2. The second iteration results in edges of length up-to 4. Similarly, after N iterations, the length of edges will be upto $2^N$.Here is an illustration after iterations:

- There can be many valid node $k$ between node $i$ and node $j$, here is an illustration

Classification Layer
We use the entity-to-entity edges (EE) of the document graph that correspond to the concept-level entity pairs to classify the concept-level entity pairs $$ \mathbf{y}=\operatorname{softmax}\left(\mathbf{W}{c} \mathbf{e}{\mathrm{EE}}+\mathbf{b}{c}\right) $$ where $\mathbf{W}{c} \in \mathbb{R}^{r \times d_{z}}$ and $\mathbf{b}_{c} \in \mathbb{R}^{r}$ are learned parameters of the classification layer and $r$ is the number of relation categories.
Result
Three models being compared:
- Edge-oriented Graph (EoG) refers to our main model with edges {MM, ME, MS, ES, SS}.
- The EoG (Full) setting refers to a model with a fully connected graph, where the graph nodes are all connected to each other, including E nodes.
- The EoG (NoInf) setting refers to a no inference model, where the iterative inference algorithm is ignored.
- The EoG (Sent) setting refers to a model that was trained on sentences instead of documents.

- Our model performs significantly better on intra- and inter-sentential pairs, even compared to most of the models with external knowledge.
- For the inter-sentence pairs, performance significantly drops with EoG(Full) and EoG(NoInf). The former might indicate the existence of certain reasoning paths that should be followed in order to relate entities residing in different sentences.
- The intra-sentence pairs substantially benefit from the document-level information.
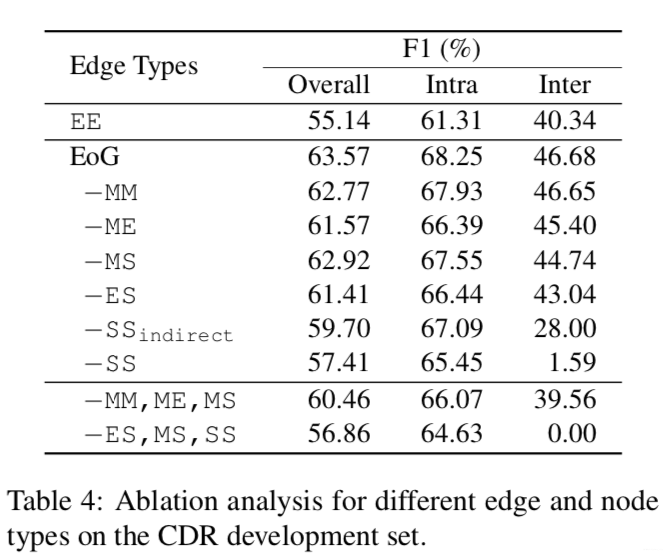
- Removal of ES edges reduces the performance of all pairs, as encoding of EE edges becomes more difficult and requires long inference paths as shown in figure (a). [we enable identification of pairs across sentences only through MM and ME edge. In this case, the minimum inference length is 6 (E-M-M-E-M-M-E)]

- As shown in figure (b), the introduction of S nodes results in a path with half the length, which we expect to better represent the relation.

- The figure above illustrates that for long-distanced pairs, EoG has lower performance, indicating a possible requirement for other latent document-level information.
Bad Cases Analysis
- The model cannot find associations between entities if they are connected by “and”.
- MIssing coreference connections.
- Incomplete entity linking.
Reference:
- Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs. https://arxiv.org/pdf/1909.00228.pdf.