Authors: Mingkai Deng, Bowen Tan, Zhengzhong Liu, Eric P. Xing, Zhiting Hu
Paper reference: https://aclanthology.org/2021.emnlp-main.599.pdf
Contribution
This paper use information alignment to define evaluation metics that is capable of measuring many key aspects of NLG tasks (dacpturing both consistency and relevance for summarization). Experiment on previously human annotated data show that their metrics achieve stronger or comparable correlations with human judgement compared to state-of-the-art metrics. [I just focus on the summarization part in the paper.]
Details
Information Alignment
Def (Information Alignment) Let $\mathbf{a}$ be a piece of text of length $N$; $\mathbf{b}$ be arbitrary data. The information alignment from text $\mathbf{a}$ to $\mathbf{b}$ is a vector of alignment scores: $$ \operatorname{align}(\mathbf{a} \rightarrow \mathbf{b})=\left\langle\alpha_{1}, \alpha_{2}, \ldots, \alpha_{N}\right\rangle $$ where $\alpha_{n} \in[0,1]$ is the confidence that the information of the $n$-th token in $\mathbf{a}$ is grounded by $\mathbf{b}$, i.e., the $n$-th token aligns with $\mathbf{b}$.
In summarization (source $x$, output $y$):
- consistency score can be defined as the average alignment scores of tokens in $y$ w.r.t. $x$, i.e. $$ \operatorname{CONSISTENCY}(\mathbf{y}, \mathbf{x})=\operatorname{mean}(\operatorname{align}(\mathbf{y} \rightarrow \mathbf{x})) $$
- Relevance can be defined as the following (I think this is measuring both precision and recall): $$ \operatorname{RELEVANCE}(\mathbf{y}, \mathbf{x}, \mathbf{r})= \operatorname{mean}(\operatorname{align}(\mathbf{r} \rightarrow \mathbf{y})) \times \operatorname{mean}(\operatorname{align}(\mathbf{y} \rightarrow \mathbf{x})) $$
Alignment Estimation
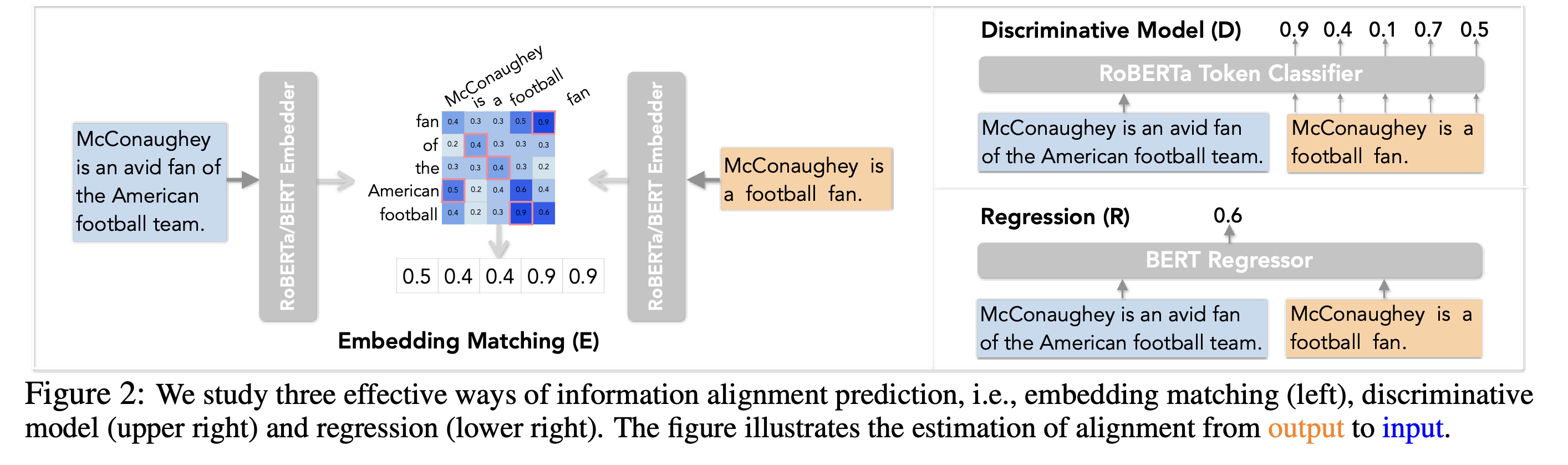
- Embedding Matching: clear in the figure.
- Discriminative Model: formulate the information alignment problem as sequence tagging.
- Aggregated Regression: similar to discriminative model, but directly estimate the single aggregated alignment score, such as mean and sum.
Training sequence tagging model
Alignment models are trained by constructing weakly supervised data using texts in the domain of evaluation. It consist of following steps:
- Prepare (input $x$, target $y$) pairs.
- Paraphrase $y$ into $y'$ to make model more robust.
- Predict randomly masked $y'$ using a generation model. Label the infilled words as “not aligned” with $x$, and other words as “aligned”.
{(($x, y'$), labels on $y'$)} will be the training data.
They use the document as x, and generate its pseudo-summaries as y using TextRank. Reference summaries are not sued since they can contain hallucinations that don’t align with the article.