Authors: James Mullenbach, Yada Pruksachatkun, Sean Adler, Jennifer Seale, Jordan Swartz, T. Greg McKelvey, Hui Dai, Yi Yang, David Sontag
Paper reference: https://arxiv.org/pdf/2106.02524.pdf
Contribution
This paper creates a clinical dataset (CLIP) over 718 randomly selected MIMIC-III discharge notes. The task is to extract all sentences having action items from these notes. It regards this task as multi-aspect extractive summarization and approaches it as a multi-label sentence classification problem given the length of each note.
The paper also explores the impact of unsupervised learning on this task. It proposes a task-targeted pre-training method that can shorten pre-training time while maintain high performance. This method is useful if effective public models does not exist for a given task.
Details
Task formulation
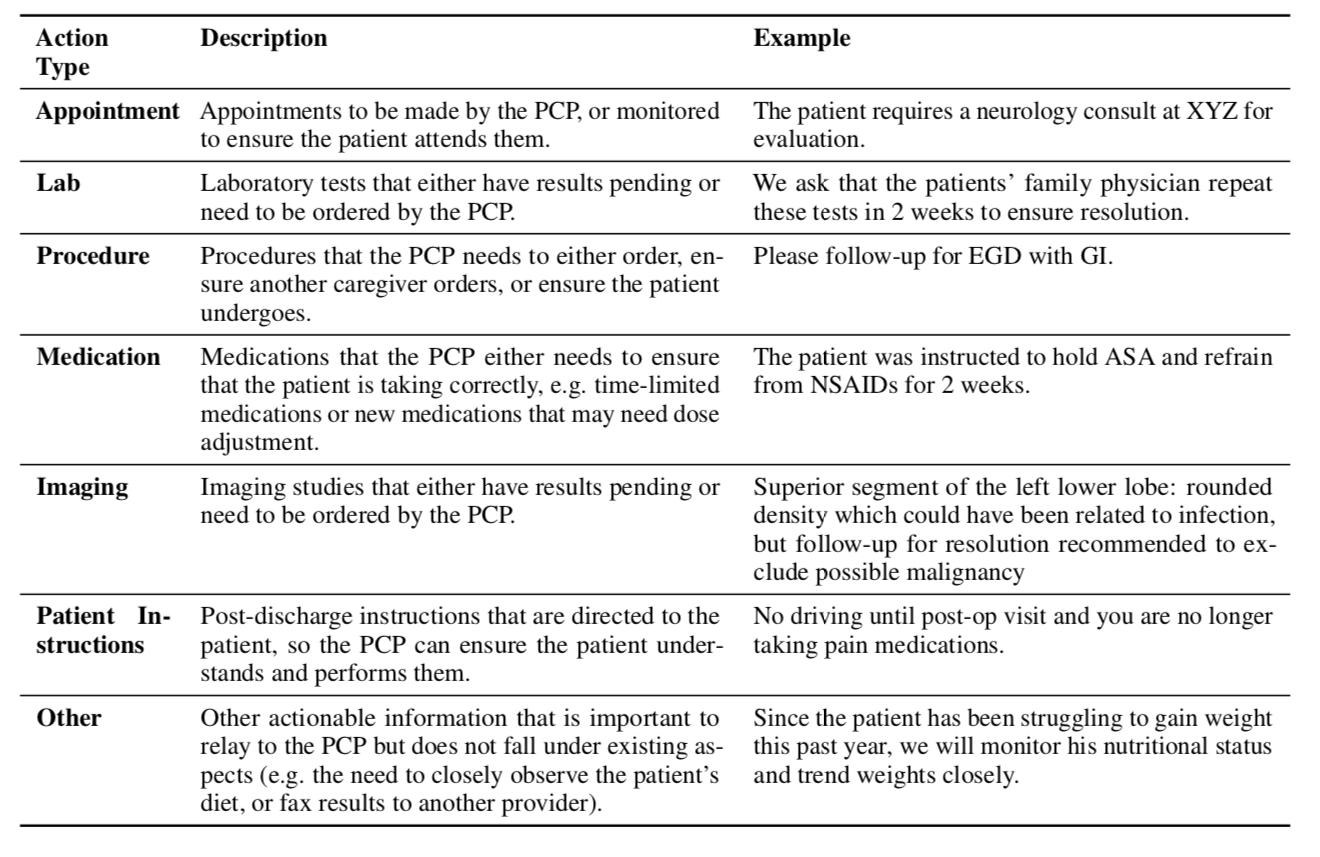
Action item: a statement in a discharge note that explicitly or implicitly directs the reader to an action that should be taken as a result of the hospital stay described in the document.
The task is to select sentences that contain action items for primary care providers (PCPs) or patients from a discharge note. Given the length of these documents and the risk of missing information, the paper approaches the task as
(1) Multi-label classification;
(2) binary-label classification (whether there exists any label in a sentence).
CLIP dataset
CLIP dataset stands for ClinicalFollowUp, which is created over MIMIC-III discharge notes.
Statistics
| # discharge notes | # sents | # sents with labels | ||
|---|---|---|---|---|
| 718 (random) | 107,494 | 12,079 |
Of the sentences with labels, 28.6% have multiple labels. There are ~150 sentences per discharge note.
| Label Type | Frequency (sentence level) |
|---|---|
| Patient Instructions | 6.55% |
| Appointments | 4.59% |
| Medications | 1.88% |
| Lab Tests | 0.69% |
| Procedures | 0.28% |
| Imaging | 0.18% |
| Other | 0.05% |
Label Type and examples
Model structures
Baselines
- BERT.
- MIMIC-DNote-BERT. BERT that further pre-trains on MIMIC-III discharge notes.
- MIMIC-Full-BERT. BERT that further pre-trains on all MIMIC-III notes.
Add neighboring context
The paper shows that the neighboring context (one left + one right) is important gien two observations:
(1) an individual sentence may not have the full picture on the type of the action;
(2) neighboring sentences tend to share the same label (occurs for 27% of sentences).
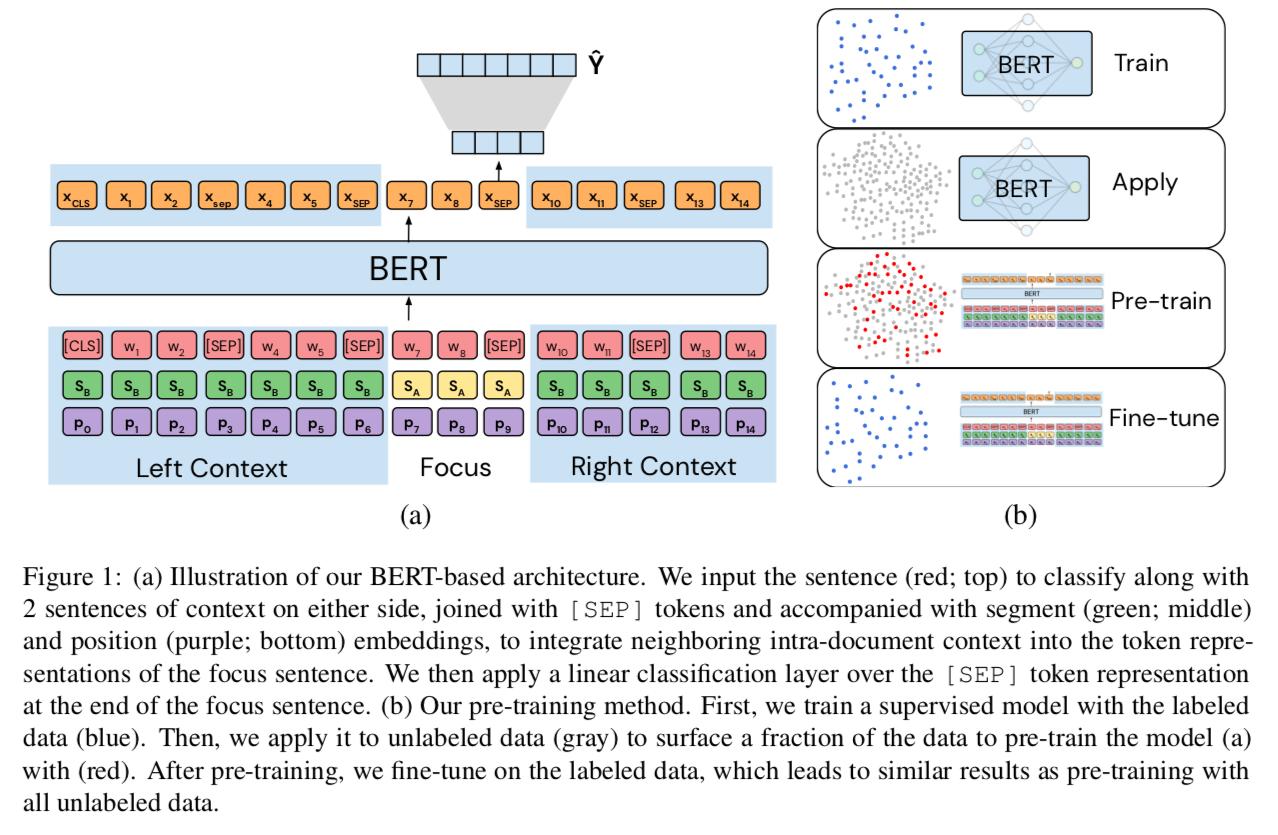
Task-targeted pre-training (TTP)
Task-targeted pre-training (TTP) uses model predictions to select sentences for pre-training. From previous study, TTP requires less data and computation, yet attains comparable performance to pre-training on large in-domain datasets.
This technique is useful in scenarios in which users have large, domain-specific, private datasets and specific tasks, and if effective public models does not exist for a given task.
Targeted Dataset Construction
(1) Fine tune a vanilla BERT model on the multilabel classification task;
(2) The learned model classifies all unlabeled sentences.
(3) Create a dataset by selecting all sentences having action items (targeted sentences) using a threshold, plus neighboring sentences.
The size the of the created dataset can vary depending on the threshold (higher for task-focused and lower for general dataset).
Second phase Pre-training
The paper pre-trains a BERT-Context model on the targeted dataset with two auxiliary tasks:
(1) MLM. Mask tokens in the context sentence only.
(2) Sentence switching. Swap the focus sentence with another randomly chosen sentence from the same document with certain probability, and predict whether the focus sentence was swapped using the context sentences.
Evaluation
Evaluation metrics are Micro/Macro F1 & AUC, and binary F1.
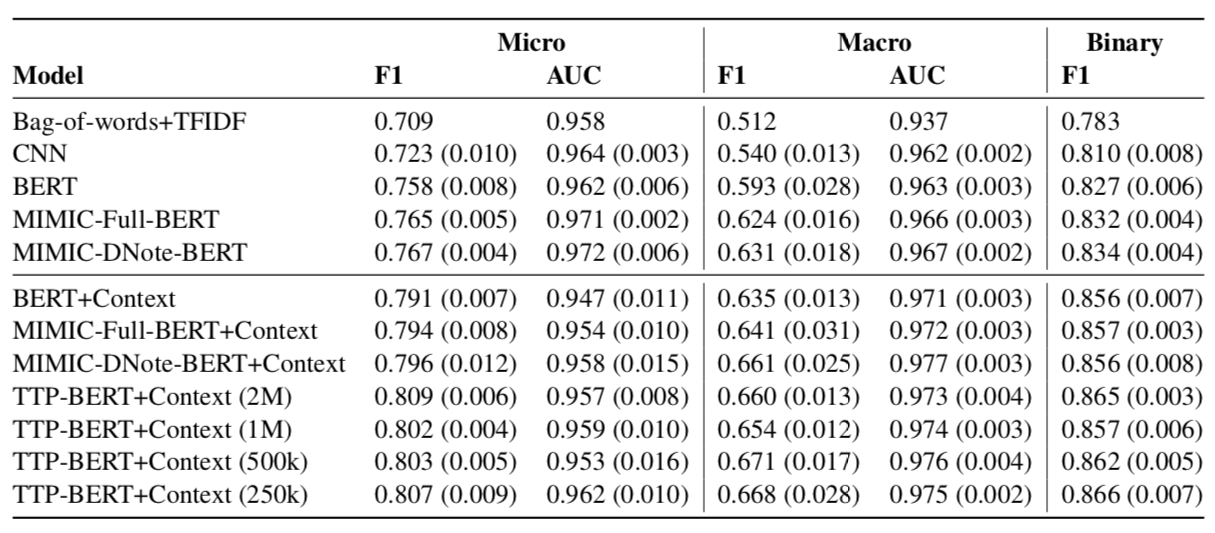
(1) The results demonstrate the importance of domain-specific pre-training.
(2) Using neighboring sentences (models with “+Context”) provides a performance boost across all metrics.
(3) When using just 250k sentences from the MIMIC discharge notes for pre-training (TTPBERT-Context 250K), task results are competitive with and in some cases exceed MIMIC-DNoteBERT+Context, which is pre-trained on all MIMIC discharge notes.
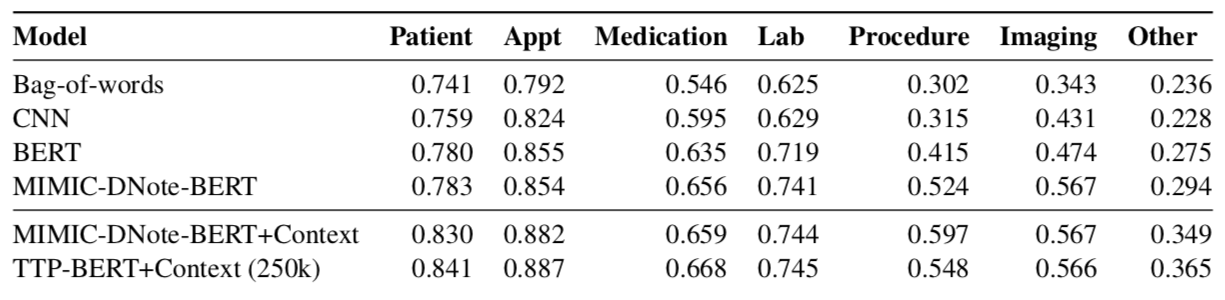
The in-domain pre-training for MIMIC-DNote-BERT models provides gains for nearly all label types, and including context also gives a boost to the F1 score of most labels.
Error Analysis
(1) Large amount of tokenization errors on clinical jargon, abbreviations, and misspellings. Add explicit clinical knowledge is necessary.
(2) Temporal Expressions.