BERT Recap
Overview
- Bert (Bidirectional Encoder Representations from Transformers) uses a “masked language model” to randomly mask some tokens from the input and predict the original vocabulary id of the masked token.
- Bert shows that “pre-trained representations reduce the need for many heavily-engineered task-specific architectures”.
BERT Specifics
There are two steps to the BERT framework: pre-training and fine-tuning
-
During pre training, the model is trained on unlabeled data over different pre-training tasks.
-
Each down stream task has separate fine-tuned models after each is first initialized with pre-trained parameters.

Input Output Representations
-
In order to handle a variety of down-stream tasks, the input must be able to represent a single sentence and sentence pair in one sequence.
-
The first token of every sequence is always a classification token
[CLS]. -
Sentence pairs are separated by a special token
[SEP]. -
Learned embeddings are added to every token indication whether it belongs to sentence A or sentence B.
Tasks
Masked Language Modeling (MLM)
- In order to train a deep bidirectional representation, they simply mask some percentage of the input tokens at random, and then predict those tokens.
- Specifically, 15% of all Word Piece tokens in each sequence are masked at random
Next sentence prediction (NSP)
- In order to train a model that understands sentence relationships, we pre-train for a binarized next sentence prediction.
- Specifically, 50% of the time, sentence B is the actual sentence that follows sentence.
results

Ablation studies
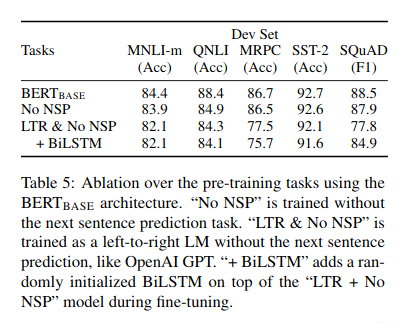
Effect of Pre-training Tasks
-
No NSP: A bidirectional model which is trained using the MLM but no next sentence prediction. This model shows to significantly hurt performance on QNLI, NMLI, and SQuAD 1.1
-
LTR and No NSP: A left-context-only model which is trained using a standard Left-to-Right LM rather than MLM. This model performs worst than the MLM model on all tasks, with large drops on MRPC and SQuAD .
Effect of Model Sizes
-
It has long been known that increasing the model size will lead to continual improvements on large-scale tasks.
-
We believe this is the first work to demonstrate convincingly that scaling to extreme model sizes also leads to large improvements on very small scale tasks.

Replication study of BERT pre training that includes the specific Modifications
-
Training the model for longer
-
Removing the Next sentence prediction objective
-
Training on longer sequences
-
Dynamically changing the masking patterns applied to the data
Training Procedure Analysis
-
Static vs Dynamic Masking:
The original BERT performed masking once during data preprocessing, resulting in a single static mask.
We compare this strategy with dynamic masking where we generate the masking pattern every time we feed a sequence

-
Model input format and Next Sentence Prediction:
The NSP loss was hypothesized to be and important factor in training the original BERT model, but recent work has questioned the necessity of the NSP loss.
They found that using individual sentences hurts performance on downstream tasks and that removing the NSP loss matches or slightly improves downstream task performance.
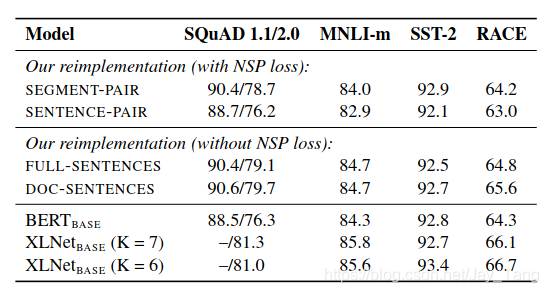
- Training with larger batches: They observe that training with large batches improves perplexity for the masked language modeling objective, as well as end-task accuracy.

RoBERTA tests and results
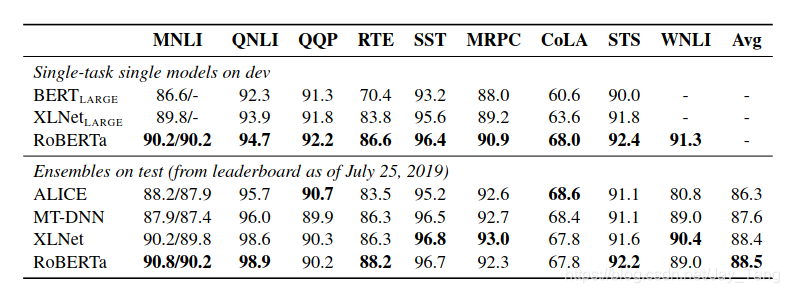
- The aggregate of the BERT improvements are combined to form RoBERTa for Robustly optimized BERT approach.
- Specifically, RoBERTA is trained with dynamic masking, FULL-SENTENCES without NSP loss, large mini-batches and a larger byte-level BPE.
Results
- RoBERTa achieves state of the art results on all 9 of the GLUE task development sets
- Crucially, RoBERTa uses the same masked language modeling pretraining-objective and architecture as BERT large, yet outperforms it.
Reference: This post is mostly written by my friend Emilio Rogalla in the NLP reading group.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding: https://arxiv.org/pdf/1810.04805.pdf
- RoBERTa: A Robustly Optimized BERT Pretraining Approach: https://arxiv.org/pdf/1907.11692.pdf