Authors: Tanya Goyal, Greg Durrett
Paper reference: https://aclanthology.org/2021.naacl-main.114.pdf
Contribution
Previous works assume that a factuality model trained on synthetic data can transfer to realistic settings. This paper investigates how factuality models (sentence-level and dependency-level classification models) trained on synthetic and human-labeled datasets perform on real generation errors.
Experiments show that, in fact, synthetic datasets do not reflect the error distributions of actual generation models, and therefore models trained on this synthetic data perform poorly when evaluated on actual generation errors although they fit the synthetic data distributions well. Instead, models trained on small amount of human annotations can significantly boost performance.
Details
Ways to create synthetic datasets
Entity-centric Synthetic Data (Ent-C)
Entity-centric synthetic data mostly consists of a few transformations: (1) Entity Swap, (2) Number Swap, (3) Pronoun Swap, (4) Negation, and (5) Paraphrase.
Generation-centric Synthetic Data (Gen-C)
The assumption for generation-centric approach is: generated paraphrases at the bottom of a paraphrasing model’s beam are more likely to contain factual errors than 1-best generations, and new information in these generations can be labeled non-factual.
Factuality Models
Given a source document $D$, a factuality model trained on synthetic/human-annotated datasets predicts whether all the information in a generated summary $S$ is supported by $D$.
Sentence-Factuality Model
Sentence-Factuality Model predicts by feeding the concatenation of the source document and the generated summary into BERT.
Arc-Factuality model
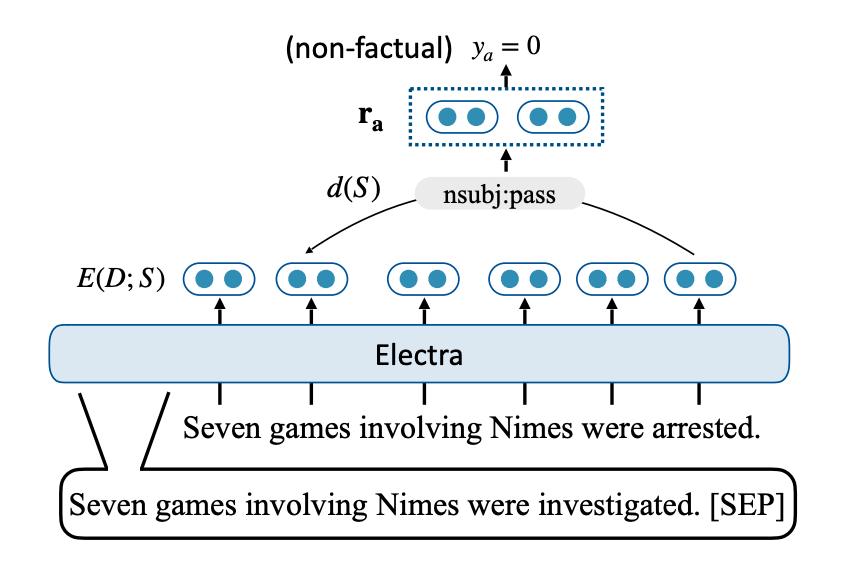
The paper uses Dependency Arc Entailment (DAE) model to evaluate factuality at the dependency arc level. The DAE model predicts whether the relationship described by the arc is entailed by the input document. If any dependency arc is non-factual, the generated summary is labeled as non-factual.
Downstream Application
This paper proposes the training objective only maximizes the likelihood of factual words in the summary and ignore the tokens with unsupported facts. Training on unsupported acts will encourage the model to hallucinate new content.